
My team doesn’t pick API protocols based on hype cycles. We pick them based on what we’ll have to live with at 3AM when something breaks in production. After migrating systems across all three paradigms rebuilding a fintech platform from REST to gRPC, layering GraphQL over a fragmented microservices mesh, and pulling GraphQL out of a startup that adopted it too early here’s the unfiltered architectural reality.
The Real Problem Nobody States Clearly
Most teams choose REST because it’s familiar, GraphQL because it’s trendy, and gRPC because a senior engineer read a Google blog post. None of those are architecture decisions. They’re social decisions dressed up in technical language.
The actual question is: who owns the contract between your services, and how much do you trust them?
Your API protocol defines the communication contract between producers and consumers. That contract has weight. It shapes team boundaries, versioning strategy, client capabilities, observability tooling, and your ability to scale independently. Get it wrong and you’re not fixing a URL structure you’re refactoring organizational trust.
REST: The Protocol That Ate the World
REST is not a specification. It’s a set of constraints statelessness, uniform interface, resource-based URIs, HATEOAS (which almost nobody implements correctly). What most teams call “REST” is actually HTTP/JSON with some conventions bolted on. That’s fine. But you need to know what you’re actually building.
Where REST wins:
- Public-facing APIs where consumers are unknown and diverse
- Teams that need to iterate quickly without coordination overhead
- Systems where caching at the HTTP layer (CDN, reverse proxy) is a first-class concern
- Anything that needs to be callable from a browser with zero tooling
The hidden architectural costs:
The endpoint explosion problem is real. A SaaS platform my team inherited had 340 REST endpoints across 12 services. No schema. No contract enforcement. Consumers were calling six endpoints to render a single dashboard page. Latency was a symptom. The disease was the protocol choice for the wrong use case.
Over-fetching and under-fetching aren’t GraphQL marketing copy they’re genuine REST failure modes at scale. When your mobile client needs user.name and user.avatar but your /users/:id endpoint returns 47 fields including nested addresses and billing history, you’re paying for bandwidth and serialization on every single call.
Versioning is where REST debt accumulates. URI versioning (/v1/, /v2/) is pragmatic but creates parallel maintenance nightmares. Header versioning is cleaner but invisible to caches. Most teams end up with a hybrid that nobody fully understands after 18 months.
Security posture: REST over HTTPS is well-understood. OAuth2 + JWT is the dominant pattern. The attack surface is predictable, tooling is mature, and every WAF on the market speaks HTTP natively. This matters more than people admit.
GraphQL: Powerful Contract, Fragile Boundary
GraphQL is not a REST replacement. It’s a query language for your API, designed to give clients precisely what they ask for and nothing more. When my team introduced it over a fragmented microservices backend for a media company, it solved the orchestration problem elegantly one typed schema, one endpoint, clients composing their own queries.
Where GraphQL wins:
- Product-facing APIs consumed by teams you control (web, iOS, Android)
- Backends-for-frontends where different clients need wildly different data shapes
- Rapid product iteration where frontend teams shouldn’t wait on backend field additions
- Systems already suffering from the N+1 endpoint problem
The architectural traps:
N+1 queries will destroy your database if you don’t implement DataLoader from day one. This is not optional. A GraphQL query requesting a list of users and their posts will, without batching, fire one query per user to resolve the posts field. My team has seen this take down staging environments within 20 minutes of load testing.
Authorization complexity is non-trivial. In REST, your authorization lives at the route level clean, auditable, easy to reason about. In GraphQL, a single query can touch eight resolvers across four domains. Field-level authorization is possible but requires discipline. Teams that don’t architect this explicitly end up with authorization logic scattered across resolvers, which becomes a security audit nightmare.
Schema governance becomes a full-time concern at scale. Who owns the schema? How do you deprecate a field without knowing every client that uses it? Schema stitching and federation (Apollo Federation specifically) solve the multi-team ownership problem but introduce significant operational complexity. My team spent two sprints just configuring the Apollo Router correctly for a federated schema across five subgraphs.
Caching is fundamentally harder. HTTP caching doesn’t apply to POST-based GraphQL queries. Persisted queries help. Apollo Client’s normalized cache helps. But you’re writing custom caching logic that REST gets for free via HTTP semantics.
Query depth and complexity attacks are a real threat. Without query complexity limits and depth limits configured at the gateway, a malicious client can craft a recursive query that brings down your entire GraphQL server. This is a production-grade concern, not a theoretical one.
gRPC: The Protocol Your Infrastructure Was Waiting For
gRPC is what happens when Google decides HTTP/JSON is too slow and too loose for internal service communication. It runs on HTTP/2, uses Protocol Buffers as the wire format, and generates strongly-typed client and server code in virtually every major language. My team uses it exclusively for internal service-to-service communication in latency-sensitive paths.
Where gRPC wins:
- Internal microservice communication where you control both sides of the wire
- Polyglot environments your Python ML service calling your Go recommendation engine
- High-throughput, low-latency paths where binary serialization matters
- Streaming use cases: server-side streaming, bidirectional streaming, real-time pipelines
The performance reality: Protocol Buffers are 3–10x smaller than equivalent JSON payloads. HTTP/2 multiplexing means multiple concurrent requests over a single connection. For an internal service making 50,000 calls per minute, these numbers compound into real infrastructure cost savings.
The architectural costs:
gRPC is opaque to standard tooling. You cannot curl a gRPC endpoint. You cannot inspect traffic in a browser. Load balancers that operate at L4 don’t understand HTTP/2 streams the way they understand HTTP/1.1. My team spent a week debugging a latency issue that turned out to be our L4 load balancer not properly handling HTTP/2 connection multiplexing.
Proto schema evolution requires discipline. You cannot change a field number in a .proto file once it’s in production. You can add fields, you can deprecate fields, but you cannot reuse numbers. Teams that don’t enforce this rigorously end up with deserialization bugs that are genuinely difficult to trace.
Browser support is limited. gRPC-Web exists but it’s a proxy-mediated compromise. If any consumer of your service is a browser, you need an envoy proxy or similar translation layer. This adds infrastructure complexity that often negates the simplicity gRPC was supposed to provide.
Error handling is less expressive. gRPC’s status codes are a fixed enumeration. REST’s HTTP status codes are more semantic, and you can attach arbitrary error bodies. For developer-facing APIs, gRPC’s error model feels stripped down.
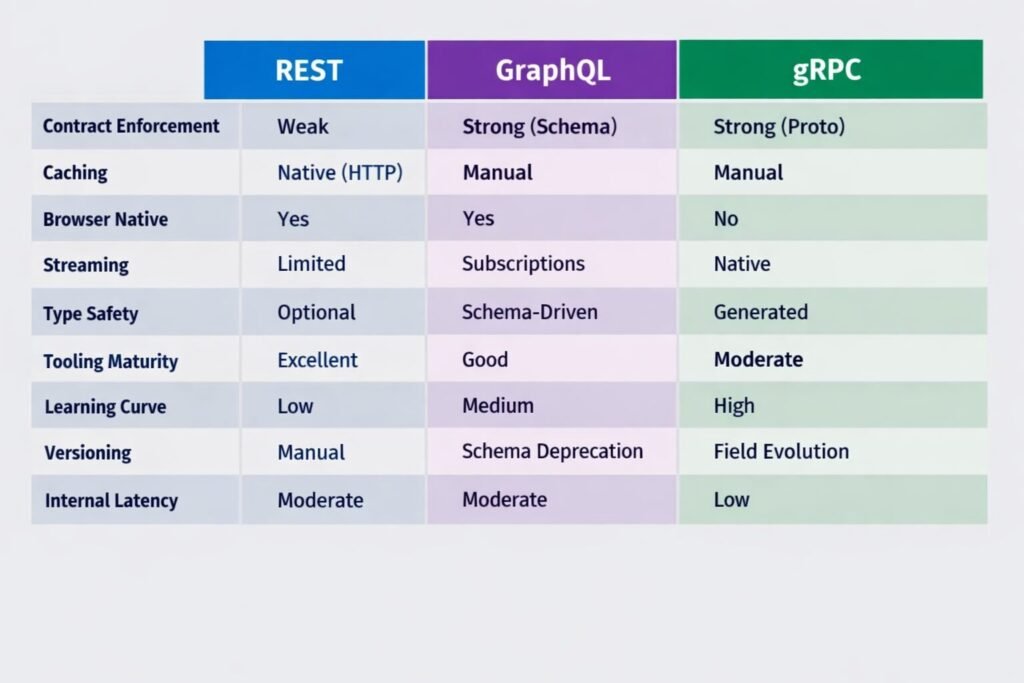
Architectural Comparison: The Honest Matrix
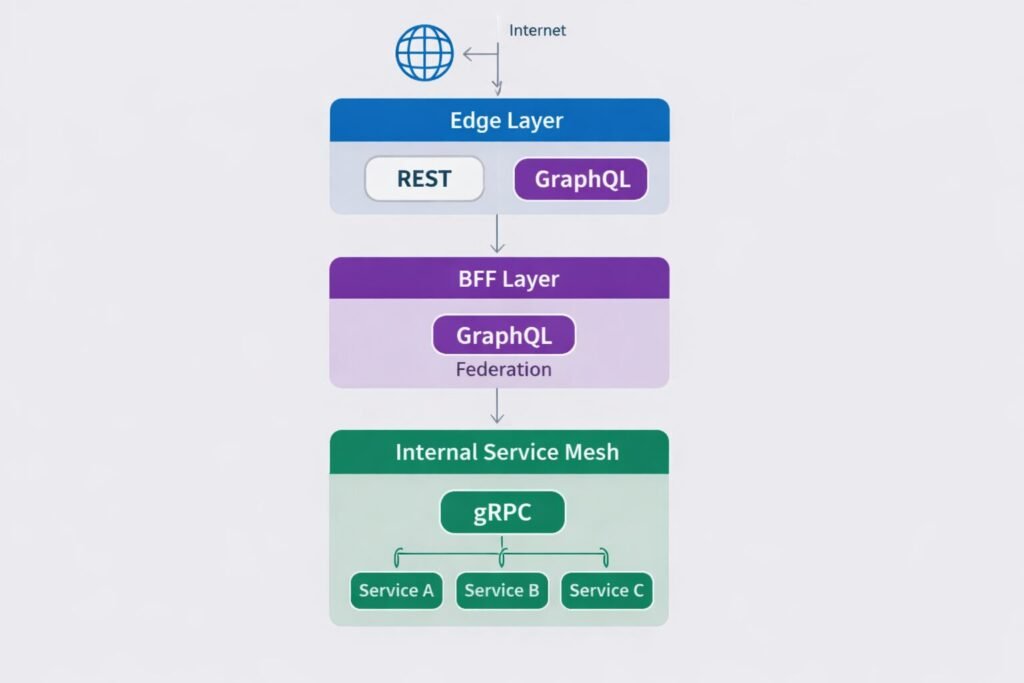
System Design: How These Protocols Layer Together
The most production-resilient architectures my team has built don’t choose one they compose all three deliberately.
The layered model looks like this:
- Edge layer (public internet → your platform): REST or GraphQL. Browser-friendly, cache-friendly, well-understood security model.
- BFF layer (gateway → product teams): GraphQL. Frontend teams own their data needs. Schema federation across bounded contexts.
- Internal service mesh (service → service): gRPC. Binary protocol, generated contracts, streaming where needed.
This isn’t complexity for complexity’s sake. Each layer is using the protocol that fits its communication pattern. The alternative forcing everything through REST produces the 340-endpoint monstrosity described earlier.
When Not to Use Each Approach
Don’t use GraphQL when:
- Your team is smaller than 8 engineers. The governance overhead isn’t worth it.
- You don’t control the clients. Public APIs with unknown consumers need REST’s predictability.
- Your data model is simple and flat. You’re adding abstraction with no payoff.
- You haven’t solved DataLoader and query complexity limiting. You’re not ready.
Don’t use gRPC when:
- You need public-facing developer APIs. The tooling story for external consumers is poor.
- Your team lacks Protocol Buffer discipline. Schema drift with
.protofiles is subtle and dangerous. - You’re on infrastructure that doesn’t handle HTTP/2 well (many managed load balancers still have quirks).
- You need rich error semantics in consumer-facing responses.
Don’t use REST when:
- You have 5+ frontend clients with divergent data needs and you’re tired of writing bespoke endpoints.
- You have high-frequency internal service calls where JSON serialization overhead is measurable.
- You need bidirectional streaming. REST is not built for that.
Enterprise Considerations
Enterprise adoption of any of these protocols has compliance, governance, and organizational dimensions that purely technical analysis misses.
Schema registries are non-negotiable at scale. Whether it’s Confluent Schema Registry for event schemas, Apollo Studio for GraphQL, or a private proto registry for gRPC, enterprises need a governed source of truth for API contracts. Without it, schema drift causes subtle, expensive integration failures.
API gateways change the equation. Kong, AWS API Gateway, Apigee, and similar products have strong REST support, growing GraphQL support, and variable gRPC support. Before committing to gRPC internally, verify that your gateway handles HTTP/2 termination and load balancing correctly for your deployment topology.
Compliance and auditability: REST’s verbose, human-readable payloads are easier to audit in transit. Binary-encoded gRPC traffic requires tooling investment to make visible to security and compliance teams. This is a real operational cost that rarely appears in protocol comparison articles.
Team skill distribution matters. A team that’s collectively fluent in REST but has one gRPC advocate is not ready to migrate internal services to gRPC. Protocol choices need to match the team’s ability to maintain, debug, and evolve them. Skill debt is technical debt.
Cost and Scalability Implications
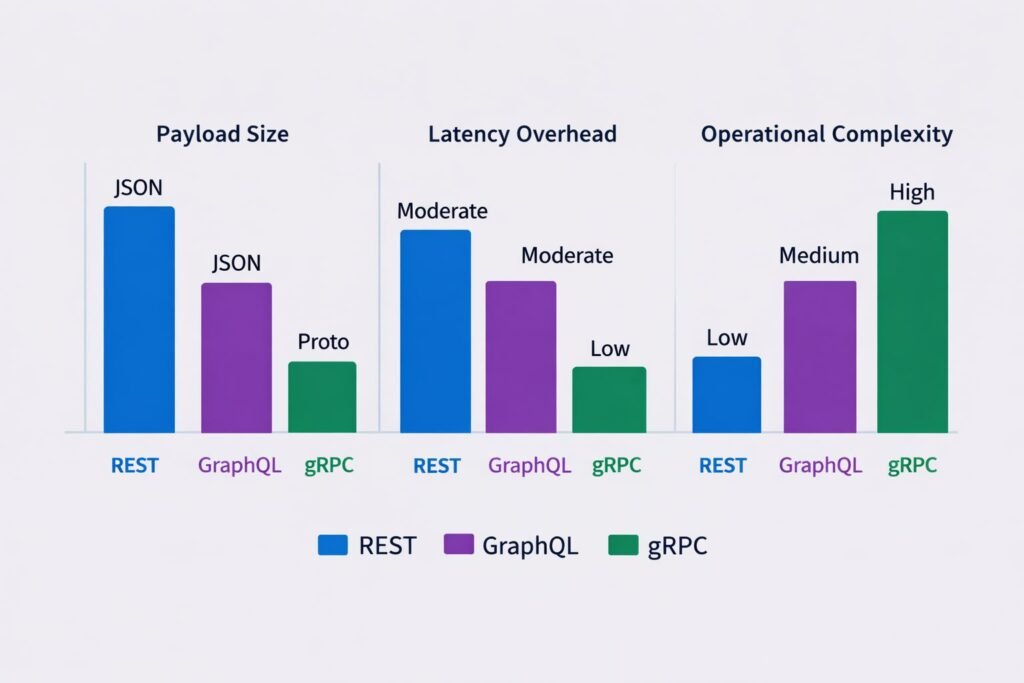
REST: Infrastructure costs are well-understood. HTTP/1.1 connection overhead is real at very high request rates connection pooling mitigates it. Caching via CDN can dramatically reduce backend load for read-heavy APIs. REST scales horizontally without protocol-specific concerns.
GraphQL: The cost center is resolver computation and database query patterns. A poorly optimized GraphQL schema will generate more database queries than an equivalent REST API, not fewer. DataLoader batching, persisted queries, and response caching (Redis-backed query caching) are required production investments. The operational cost of running Apollo Studio or equivalent schema governance tooling is real expect $500–$2,000/month for enterprise-grade observability.
gRPC: Binary serialization reduces compute cost per request. HTTP/2 multiplexing reduces connection overhead. For services making tens of millions of internal calls per day, the infrastructure savings from gRPC vs REST are measurable my team observed a 23% reduction in internal network egress after migrating a high-frequency pricing service to gRPC. The cost is in infrastructure complexity: Envoy sidecar proxies, proper HTTP/2 load balancing configuration, and proto schema tooling.
Common Mistakes Engineers Make
With REST: Not treating OpenAPI specs as first-class artifacts. Inconsistent error response shapes across services. Forgetting that PATCH and PUT semantics are different. Versioning by URL when you should be versioning by content negotiation (or vice versa).
With GraphQL: Shipping to production without query depth limits. Skipping DataLoader because the team is “moving fast.” Letting the schema become a mirror of the database schema instead of a model of the product domain. Using subscriptions for everything when polling would suffice.
With gRPC: Changing proto field numbers in backward-incompatible ways. Not generating clients from the proto hand-writing them instead. Running gRPC behind an L4 load balancer and wondering why streaming doesn’t work. Forgetting that deadlines/timeouts need to be propagated across service calls.
Implementing This Correctly: A Strategic Path
The teams my team has helped untangle API architecture debt all share one failure mode: they made a single protocol decision and applied it universally. The fix is contextual protocol assignment.
Step one: Map your API consumers. Browser clients, mobile apps, internal services, partner integrations, and webhooks all have different protocol needs. Write them down.
Step two: Identify your pain points. Are you suffering from over-fetching? Under-fetching? Schema drift? Latency on internal calls? Each problem maps to a protocol solution.
Step three: Implement a schema-first culture regardless of protocol. REST uses OpenAPI. GraphQL uses SDL. gRPC uses .proto. The spec is the contract. The contract precedes the code.
Step four: Instrument before you optimize. You cannot make an informed protocol migration decision without latency percentiles, payload size distributions, and query patterns from production traffic.
Step five: Treat API architecture as a product, not an implementation detail. It has consumers, it has versioning, it has backward compatibility obligations. Teams that internalize this ship better APIs faster because they’re not constantly apologizing for breaking changes.
Your API layer is the surface area through which your entire system expresses itself to the world. Choosing its protocol thoughtfully matching it to your communication patterns, your team’s capabilities, and your scalability trajectory is one of the highest-leverage architectural decisions you’ll make. It compounds over years. Make it deliberately.
Checkout Our Full Guide : The Complete Guide to API Design in Production Systems 2026

Finly Insights Team is a group of software developers, cloud engineers, and technical writers with real hands-on experience in the tech industry. We specialize in cloud computing, cybersecurity, SaaS tools, AI automation, and API development. Every article we publish is thoroughly researched, written, and reviewed by people who have actually worked in these fields.


