
Executive Summary
Idempotency is not a feature — it is a correctness guarantee. When payment services double-charge customers, when inventory systems create duplicate orders, or when notification pipelines fire twice, the root cause is almost always the same: an API that was never designed to handle retries safely. This article breaks down how my team architects idempotent APIs in production SaaS systems, the trade-offs involved, and where most engineering teams get it wrong.
The Real Problem This Solves
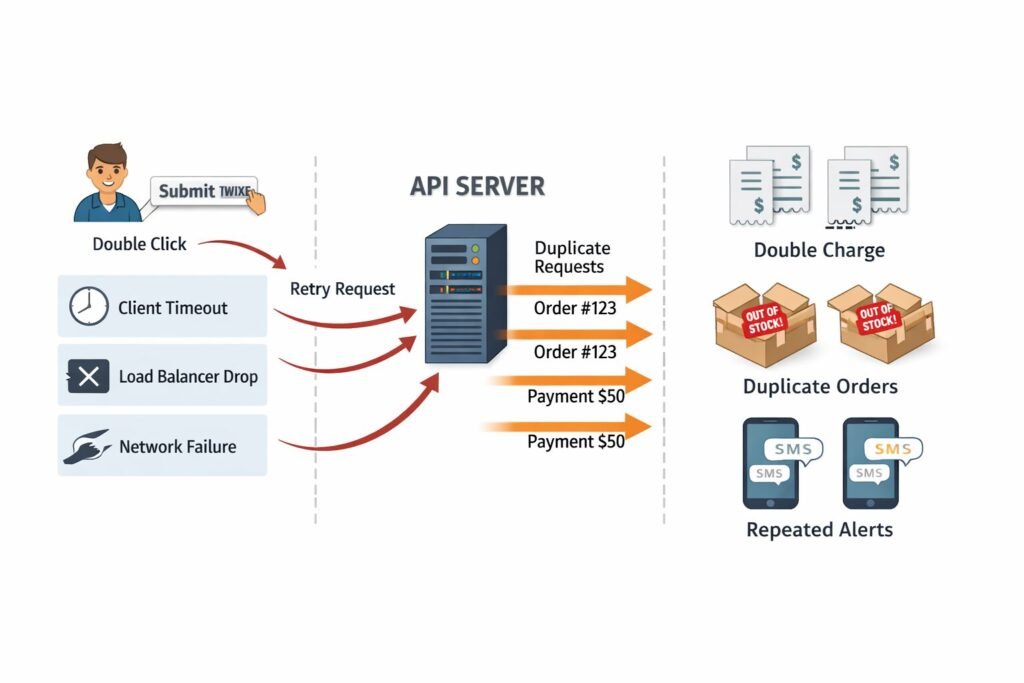
Networks fail. Clients timeout. Load balancers drop connections mid-request. In every distributed system, any operation that mutates state will eventually be retried — by the client, by a message queue, by an orchestration layer, or by an anxious user clicking “Submit” twice.
The question is never whether a request will be duplicated. It is whether your API is prepared for it.
Stripe loses millions of dollars in trust — not revenue, trust — every time a duplicate charge lands on a customer’s statement. Inventory systems at e-commerce scale oversell products because two concurrent POST /orders requests both read the same stock count before either write commits. Notification systems send the same SMS six times because a Lambda function retried after a downstream timeout.
These are not edge cases. They are the default behavior of distributed systems under load. If you are building a scalable REST API for SaaS applications, this is not optional architecture — it is table stakes.
The Architecture of Idempotency
The Idempotency Key Pattern
The most battle-tested approach is client-supplied idempotency keys. The client generates a unique key (typically a UUID v4) and attaches it to the request header. The server uses this key to deduplicate.
POST /v1/payments
Idempotency-Key: a3f9b2c1-4e87-4d2a-9b3c-1f8e7d6c5a4b
Content-Type: application/json
{ "amount": 5000, "currency": "usd", "customer_id": "cus_123" }On the server side, before executing the business logic, you check a fast store (Redis is the standard choice) for a record of this key. If it exists and the operation completed, you return the stored response. If it exists but is still processing, you return a 409 Conflict or a 202 Accepted with a polling URL. If it does not exist, you lock the key, execute the operation, store the result, and return it.
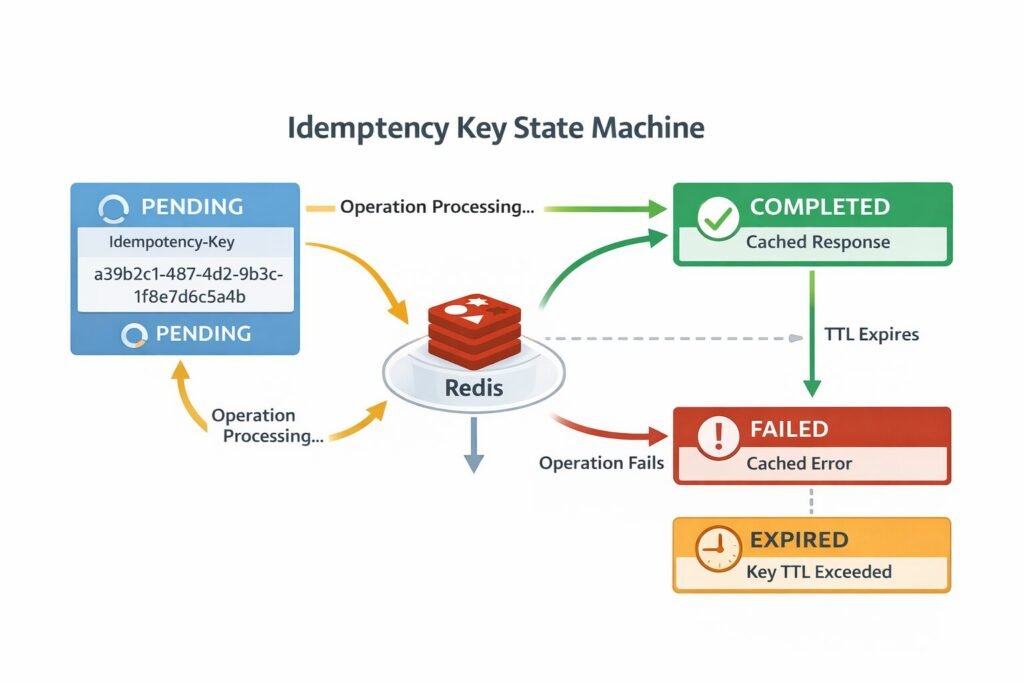
The state machine for this flow:
PENDING— Key received, operation in progressCOMPLETED— Operation finished, response cachedFAILED— Operation failed, result cached (yes, cache failures too)EXPIRED— Key TTL exceeded, treated as new request
Caching failures is a detail most teams miss. If a payment fails due to insufficient funds, you want to return that same failure on retry — not re-attempt the charge and create a confusing second declined transaction in the customer’s bank history.
The Storage Layer Decision
Where you store idempotency records directly determines your system’s behavior under failure.
Redis is the right choice for most teams. It gives you sub-millisecond lookups, atomic SET NX operations (set-if-not-exists), and built-in TTL expiry. The SET key value NX PX 86400000 command atomically creates the key only if it does not already exist, which eliminates the check-then-set race condition that plagues naive implementations.
PostgreSQL is the right choice when you need transactional consistency between your idempotency record and your business data. You insert the idempotency record and create the order in the same database transaction. If the transaction rolls back, neither record exists. This is stronger than Redis but slower.
The hybrid approach — which is what my team runs in production — uses Redis for the fast lock and PostgreSQL for the durable record. Redis catches duplicate requests within milliseconds. Postgres ensures the record survives a Redis eviction or restart.
Key Engineering Decisions and Trade-offs
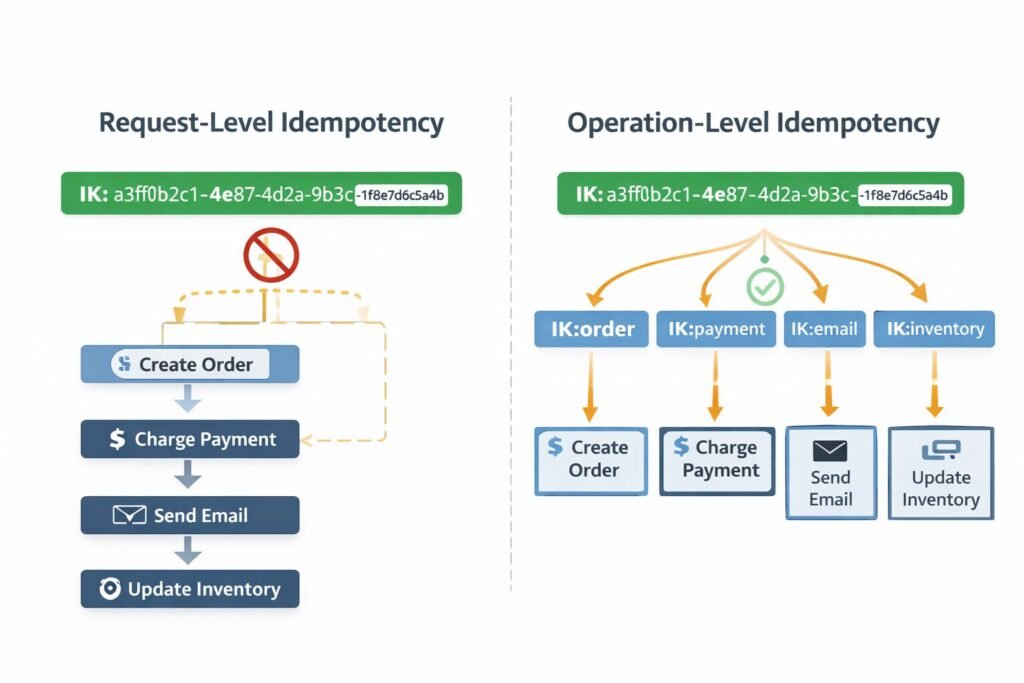
Scope: Request-Level vs. Operation-Level
Most teams implement idempotency at the HTTP request level. That is the right starting point, but it is not sufficient at scale.
Consider a request that triggers multiple downstream operations: create order, charge payment, send confirmation email, update inventory. If the server crashes after the payment succeeds but before the inventory update runs, a retry will attempt to charge the customer again — even with a request-level idempotency key — because the entire request is considered incomplete.
The more robust approach is operation-level idempotency: each sub-operation within a request has its own idempotency guarantee. My team implements this using a derived key strategy. Given a top-level idempotency key IK, downstream operations receive keys like IK:payment, IK:inventory, IK:email. Each service checks its own derived key independently.
This turns a fragile all-or-nothing guarantee into a resumable workflow that can pick up exactly where it left off. This pattern becomes especially critical when you integrate Stripe usage-based billing with Next.js, where partial failures between billing and fulfillment are a real operational risk.
TTL Strategy
How long do you store idempotency records? This is a product decision disguised as a technical one.
Stripe uses 24 hours. That covers automatic retry windows, client-side retry logic, and human intervention timescales. For most SaaS APIs, 24 hours is the right default.
For financial systems where regulations require audit trails, you may store idempotency records for 90 days — but in a separate cold store, not in Redis. Keeping 90 days of keys in Redis is expensive. Archive completed records to PostgreSQL or S3 after 24 hours and query there for historical lookups.
For high-frequency APIs (thousands of requests per second), even 24 hours of keys can consume significant Redis memory. At 100 bytes per record and 10,000 RPS, you are storing 86 billion bytes per day — 86 GB — before accounting for Redis overhead. Size your records carefully.
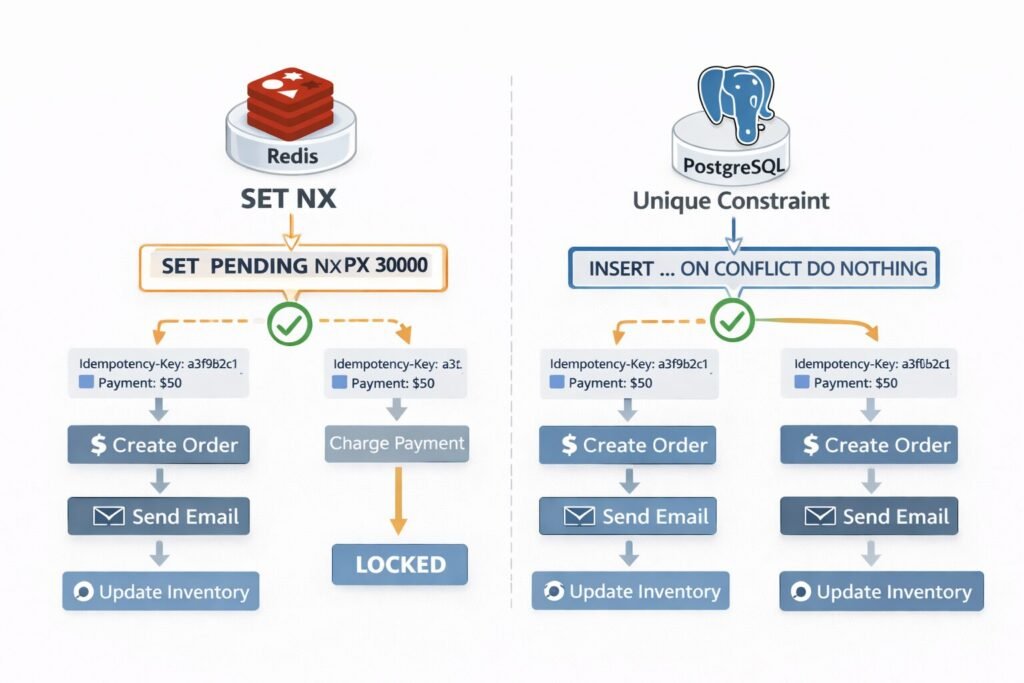
Concurrency: The Double-Submit Problem
The hardest problem in idempotency implementation is what happens when two identical requests arrive simultaneously, before either has written a result.
The naive solution — check if key exists, then insert — is a race condition. Both requests check, both see nothing, both proceed, and you have duplicated the operation.
The correct solution uses atomic operations:
In Redis, SET key PENDING NX PX 30000 will succeed for exactly one of two concurrent requests. The other gets a nil response and knows to wait or return a 409.
In PostgreSQL, use a unique constraint on the idempotency key column combined with INSERT ... ON CONFLICT DO NOTHING and check the affected row count.
My team wraps this in a distributed lock with a short TTL (30 seconds) that covers the expected maximum operation time. If the lock expires and the operation is still not complete, the system assumes the original request crashed and allows a retry.
Security Implications
Idempotency keys introduce an attack surface that is easy to overlook.
Key exhaustion: A malicious client could flood your system with unique keys for operations that are never retried, consuming storage. Rate-limit key creation per user/tenant, not just per IP. My team’s approach to API rate limiting strategies for high-traffic applications covers this threat model in detail — idempotency key abuse fits squarely into the same mitigation patterns.
Key prediction: If keys are predictable (sequential integers, timestamps), an attacker could replay or preempt legitimate requests. Enforce UUID v4 or equivalent entropy. Reject keys under 16 characters.
Cross-tenant key isolation: Idempotency keys must be scoped to an authenticated identity. A key from user A must never match a key from user B, even if they submit the same string. Always prefix stored keys with the tenant or user ID: tenant_123:a3f9b2c1-...
Response replay: Returning a cached response to a retry is correct behavior — but verify that the requester is the same authenticated identity who made the original request. Do not return cached responses to unauthenticated or differently-authenticated retries. This intersects directly with how you handle OAuth 2.0 in your API — your token validation layer and your idempotency layer must work in concert, not independently.
The broader question of securing APIs with OAuth 2.0 and JWT is inseparable from idempotency security. A perfectly implemented idempotency layer is worthless if the authentication layer allows token reuse or replay attacks. Make sure you also understand what a JWT is in an API context and the safest way to store JWT tokens — these decisions affect how safely your idempotency keys can be scoped and validated.
Performance Bottlenecks
The Redis Round-Trip Tax
Every idempotent endpoint adds one Redis round-trip before business logic executes. At 1ms Redis latency and 5,000 RPS, that is 5 seconds of Redis time per second — which means you need Redis connection pooling sized appropriately, and you need to treat Redis availability as a critical path dependency.
If Redis is unavailable, you have two options: fail open (process the request without idempotency guarantees, accepting potential duplicates) or fail closed (return a 503 and force the client to retry later). For financial operations, always fail closed. For read-heavy or low-stakes operations, failing open is acceptable.
Thundering Herd on Hot Keys
When a popular idempotency key is being checked concurrently (for example, a webhook that fires thousands of times for the same event), you can see thundering herd behavior on that single Redis key. Use a short exponential backoff on the client side and consider a Lua script on Redis to atomically check-and-set in a single round-trip, reducing contention. Teams running on Cloudflare Workers vs Vercel Edge Functions will encounter this pattern differently depending on the edge runtime’s connection model to Redis — it is worth benchmarking both.
Common Mistakes My Team Has Seen
- Not caching error responses. If a payment fails, cache the failure. Do not re-attempt on retry.
- Scoping keys globally instead of per-tenant. This creates cross-tenant data leaks.
- Using request body hash as the idempotency key. The server should not compute the key — the client should supply it. Body hashing does not account for timing or user intent.
- Setting the TTL too short. A 5-minute TTL does not cover client retry windows that can extend hours in enterprise systems.
- No idempotency on webhook delivery. Webhooks are retried by definition. Your webhook consumers must implement idempotency, not just your API.
- Treating idempotency as optional. Teams bolt it on after a duplicate charge incident. Build it into the API contract from day one. This is especially true when you implement rate limiting for an API — both concerns belong in the initial design, not as afterthoughts.
When Not to Use This Approach
Idempotency keys add latency and storage overhead. There are cases where the trade-off is not worth it:
Pure read operations (GET requests) are inherently idempotent. Do not add key infrastructure to them.
High-frequency event streams where duplicates are acceptable — telemetry, analytics events, logging — do not need this level of guarantee. Use deduplication at the consumer level with a time window instead.
Operations with natural idempotency — setting a value to a specific state rather than incrementing it — do not need explicit key management. PUT /users/123/status { "status": "active" } is safe to retry without a key because the result is the same regardless of how many times it runs. Understanding when REST vs GraphQL vs gRPC is the right protocol choice also shapes which operations carry natural idempotency and which do not.
Internal synchronous microservice calls within a single transaction boundary can rely on database transaction semantics rather than application-level idempotency.
Enterprise Considerations
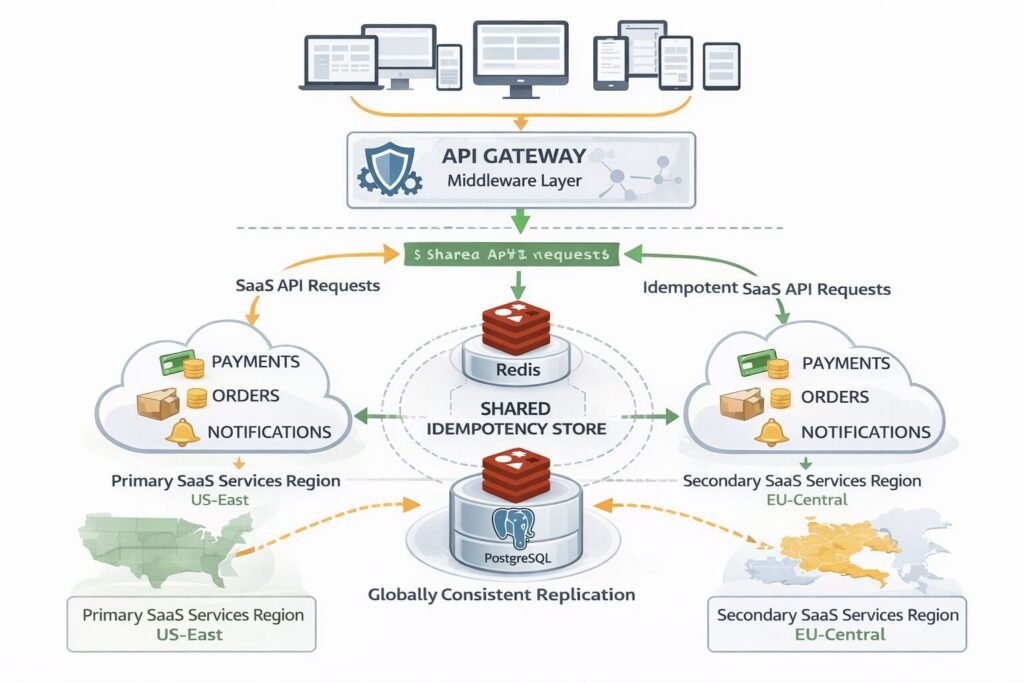
At enterprise scale, idempotency infrastructure becomes a platform concern, not a per-service concern.
My team centralizes idempotency handling in an API gateway middleware layer. Every service behind the gateway gets idempotency for free, with a shared Redis cluster and a consistent response schema. Services opt out explicitly for the cases listed above, rather than opting in. This architectural approach aligns with how we think about the complete guide to API design for production systems — platform-level guarantees beat per-service implementations every time.
For multi-region deployments, the idempotency store must be globally consistent or you accept the risk of region-split duplicates. Most teams choose eventual consistency with a small duplicate window rather than paying the latency cost of synchronous cross-region writes. This is the right call for most SaaS workloads. For payment systems, use a strongly consistent global store (CockroachDB or Google Spanner) and accept the latency.
Audit and compliance: Store idempotency records with full request/response snapshots for regulated industries. This gives you a complete replay log of every mutation, which satisfies SOC 2, PCI-DSS, and HIPAA audit requirements more cleanly than traditional logging.
SLA implications: Document your idempotency guarantees in your API contract. Specify the key TTL, the scope of the guarantee, and the behavior when a key expires. Enterprises integrating with your API need to build their retry logic around these documented guarantees. If you are building and documenting APIs using OpenAPI, idempotency behavior — including key TTL and error response schemas — belongs in the spec, not just in a README.
Cost & Scalability Implications
A single Redis node handles millions of idempotency key lookups per day with negligible cost. The real cost driver is storage growth.
At 10,000 requests per day with a 24-hour TTL and 200-byte average record size, you are storing 2 MB of idempotency data at any point. At 1 million requests per day, that becomes 200 MB — still trivial for Redis.
The inflection point is typically around 100 million requests per day, where you need to think carefully about Redis memory budgeting. At that scale, compress the stored response payload (gzip reduces most JSON responses by 60–80%), use shorter keys, and archive records aggressively to cold storage after the active window closes.
For multi-tenant SaaS, implement per-tenant storage quotas on idempotency records. A tenant running a buggy integration that generates millions of unique keys should not exhaust shared Redis memory. Teams evaluating GraphQL vs REST for SaaS should factor in that GraphQL’s single-endpoint model makes idempotency key scoping more complex — you are deduplicating at the operation level, not the URL level, which adds overhead to the storage key design.
Implementing This Correctly: A Strategic Perspective
Idempotency is not a feature you ship in a sprint. It is an architectural commitment that shapes how your entire API surface behaves under failure.
My team approaches it in three phases. First, identify every state-mutating endpoint and classify it by risk: financial operations, inventory mutations, and communication triggers are high-risk and get full idempotency infrastructure. Lower-risk operations get natural idempotency through PUT semantics where possible.
Second, build idempotency as platform infrastructure, not per-endpoint logic. A middleware layer that every service inherits is far more maintainable than bespoke implementations scattered across a codebase.
Third, test failure scenarios explicitly. Chaos engineering your idempotency layer — killing the server mid-operation, simulating Redis unavailability, firing concurrent duplicate requests — is the only way to verify that the guarantees hold in production.
APIs are long-term strategic assets. An API that handles failure gracefully earns the trust of enterprise integrators, reduces support burden, and enables the kind of reliable automation that makes your platform genuinely programmable. Idempotency is one of the highest-leverage investments you can make in API quality, and it pays dividends for the lifetime of the interface. If you are building automation workflows on top of your API, patterns like building automated meeting workflows with AI agents demonstrate exactly why retry-safe operations are non-negotiable — every automation layer assumes it can safely retry.
Build it in from the start. Retrofitting it is possible, but it is painful — and the incident that forces the conversation is always more expensive than the engineering time to prevent it.

Finly Insights Team is a group of software developers, cloud engineers, and technical writers with real hands-on experience in the tech industry. We specialize in cloud computing, cybersecurity, SaaS tools, AI automation, and API development. Every article we publish is thoroughly researched, written, and reviewed by people who have actually worked in these fields.


