
Executive Summary
Most API development teams write code first and document later. The documentation never fully catches up, the contract drifts from implementation, and every integration becomes a negotiation between what the docs say and what the API actually does. Contract-first development inverts this entirely — the contract is the source of truth, the code is derived from it, and the gap between documentation and behavior closes to zero. This article covers how my team implements contract-first development in production SaaS systems and why it changes the economics of API integration fundamentally.
The Real Problem This Solves
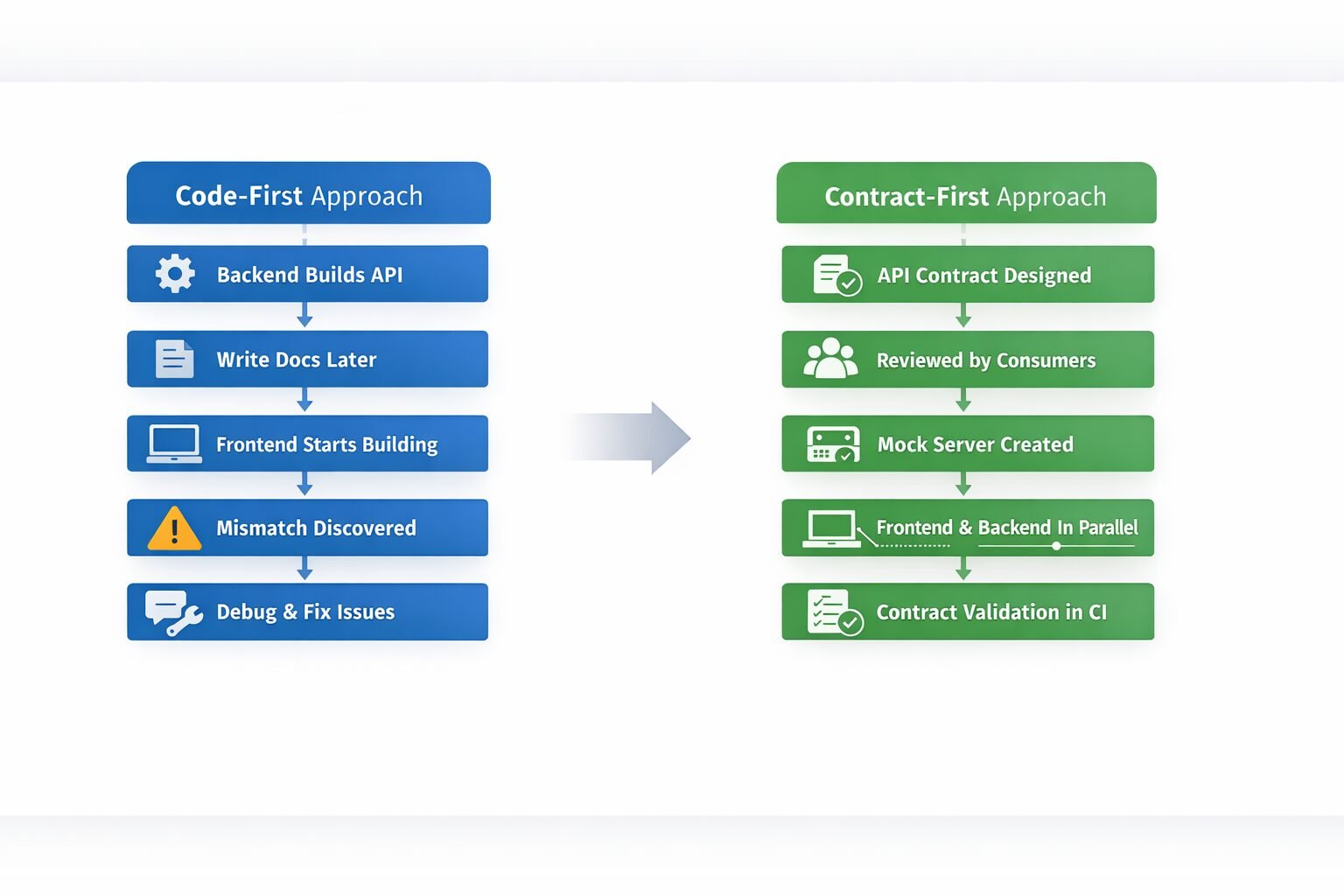
Consider what happens in a typical code-first API workflow. A backend engineer builds an endpoint, writes some documentation in a README or a Confluence page, and hands it off to the frontend team or an integration partner. The frontend team starts building. Midway through, they discover that the response shape does not match the documentation. The backend engineer clarifies verbally. The documentation does not get updated. Three months later, a new engineer joins the frontend team, reads the documentation, builds against it, and hits the same mismatch. The cycle repeats indefinitely.
This is not an edge case — it is the default state of every code-first API team that does not enforce documentation discipline rigorously. And documentation discipline is notoriously difficult to maintain because it is a secondary task that competes with the primary task of shipping features.
The deeper problem is that code-first development delays the discovery of interface problems. By the time a frontend engineer or integration partner hits a poorly designed response structure, the backend implementation is already in production. Changing it now means a versioning event, a migration guide, client outreach, and weeks of parallel support. The cost of a bad design decision scales with how late it is discovered. Contract-first development moves discovery as early as possible — before any code is written.
My team has shipped both ways. The productivity difference in integration-heavy environments is not marginal. It is structural.
What Contract-First Development Actually Means
Contract-first means the API specification is written, reviewed, and agreed upon before any implementation code is written. The specification is not documentation of the implementation — it is the design artifact from which the implementation is derived.
In practice, this means:
The API contract — typically an OpenAPI specification — is the first deliverable on any new API work. It defines every endpoint, every request schema, every response schema, every error code, and every authentication requirement before a route handler exists.
The contract is reviewed by every stakeholder who will consume the API — frontend teams, mobile teams, integration partners, QA — before implementation begins. Design problems surface in a document review, not in a production incident.
Mock servers are generated from the contract on day one. Consumer teams build against the mock without waiting for the backend implementation. Frontend development and backend development run in parallel instead of sequentially.
Server-side validation, client SDKs, and documentation are generated from the contract automatically. The contract is the single source of truth that everything else derives from.
The OpenAPI Specification as a Design Tool
OpenAPI is the dominant specification format for REST APIs and the foundation of contract-first development in my team’s systems. But OpenAPI is only a design tool if you write it before the code, not after.
Designing Request and Response Schemas
The most valuable exercise in contract-first development is designing response schemas without the pressure of an existing implementation. When you design schema after implementation, you document what the code returns. When you design schema before implementation, you design what the consumer actually needs.
My team runs schema design sessions that include backend engineers, the primary API consumers, and a technical writer. The questions that drive these sessions:
- What is the minimum information a consumer needs from this response to complete their workflow?
- What field names will consumers expect based on domain vocabulary?
- Which fields will change frequently versus which are stable?
- What are the error states and what information does a consumer need to handle each one?
These questions produce materially different schemas than “what does the database return.” They produce schemas optimized for the consumer’s mental model, not the server’s data model. Connecting this directly to API naming conventions — contract-first design is where naming decisions get made deliberately, before they become permanent implementation artifacts.
A partial OpenAPI schema for a payment endpoint looks like this in practice:
paths:
/payments:
post:
operationId: createPayment
summary: Create a new payment
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/CreatePaymentRequest'
responses:
'201':
description: Payment created successfully
content:
application/json:
schema:
$ref: '#/components/schemas/Payment'
'422':
description: Validation failed
content:
application/json:
schema:
$ref: '#/components/schemas/ErrorResponse'The schema references — $ref — point to reusable component definitions. My team defines all request and response schemas as named components rather than inline definitions. This makes schemas reusable across endpoints, keeps the path definitions readable, and enables consistent schema evolution.
Schema Reuse and Composition
One of the structural advantages of writing the contract first is that you design for reuse intentionally rather than discovering opportunities for reuse after the fact.
My team uses three OpenAPI composition patterns consistently:
$ref for shared schemas. A User object that appears in five different response types is defined once and referenced five times. When the User schema changes, it changes in one place.
allOf for schema inheritance. A PaymentMethod base schema extended by CardPaymentMethod and BankPaymentMethod variants. This models polymorphic responses cleanly without duplicating shared fields.
oneOf for discriminated unions. When an endpoint can return different response shapes depending on a type field — common in event-driven API designs — oneOf with a discriminator property models this correctly in the spec.
These patterns are much easier to apply in a contract-first workflow because you are designing the schema relationships deliberately. In a code-first workflow, you are often retrofitting schema composition onto response structures that were designed independently by different engineers.
The Mock Server: Decoupling Frontend and Backend Development
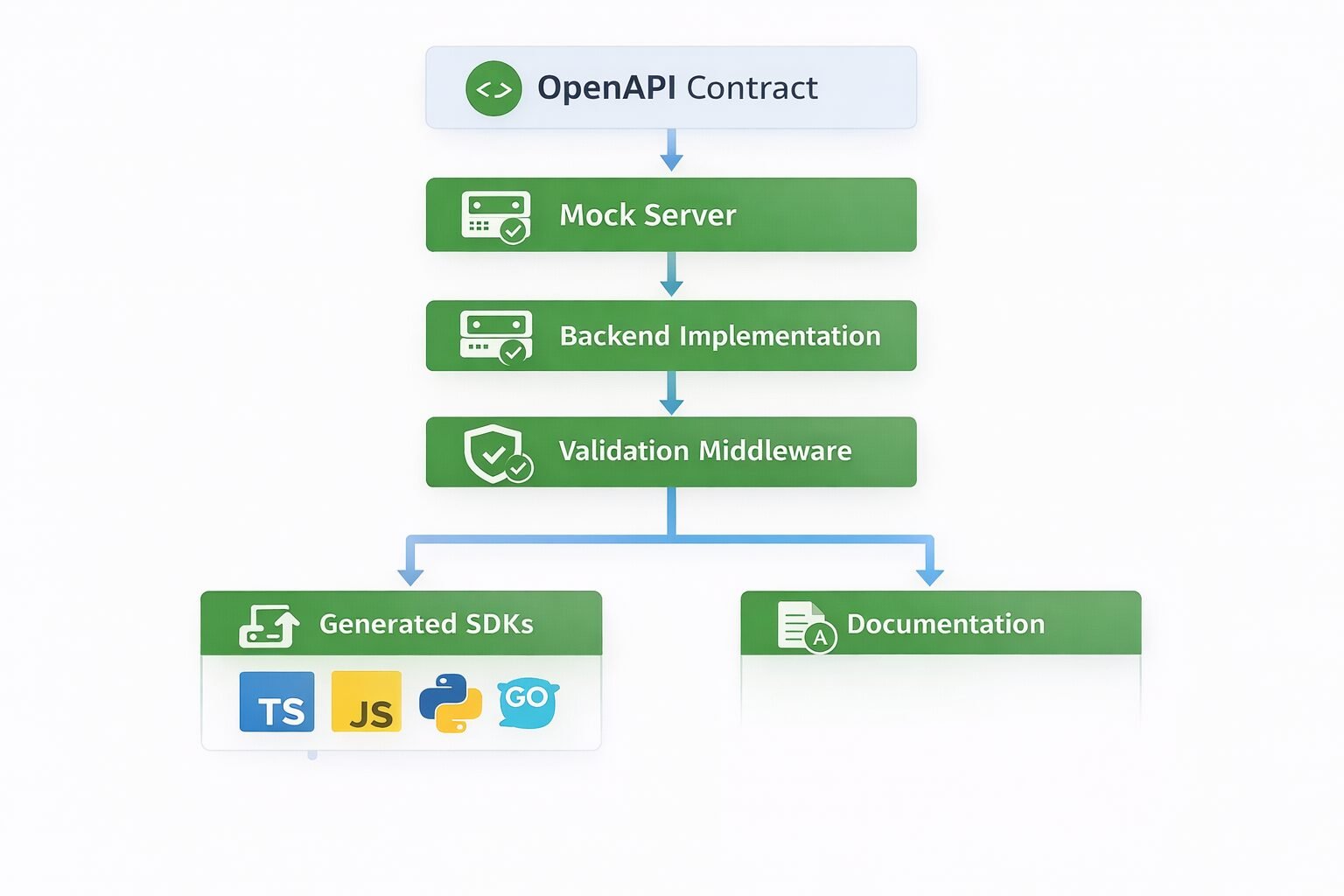
The most immediate productivity gain from contract-first development is the ability to generate a mock server from the specification on day one.
Tools like Prism, Stoplight, and WireMock read an OpenAPI specification and generate a server that returns example responses for every defined endpoint. Consumer teams — frontend engineers, mobile developers, integration partners — can build against this mock immediately, without waiting for backend implementation.
This eliminates one of the most common productivity bottlenecks in API-driven product development: frontend engineers blocked on backend engineers. In a code-first workflow, frontend development cannot begin until the backend endpoint exists. In a contract-first workflow, both begin simultaneously from the same contract.
My team’s workflow looks like this:
The contract is merged to main. An automated pipeline generates the mock server and deploys it to a staging environment within minutes. Frontend teams receive the mock server URL and begin development. Backend teams begin implementing against the same contract. Integration tests validate that the backend implementation matches the contract before deployment.
The mock server also serves as the integration test baseline. If a backend implementation diverges from the contract — returns a field with the wrong type, omits a required field, returns a different status code — the contract validation step in CI catches it before it reaches staging.
This integrates naturally with automated testing approaches — contract validation is a first-class test type that lives alongside unit tests and integration tests in your CI pipeline.
Contract Validation in CI/CD
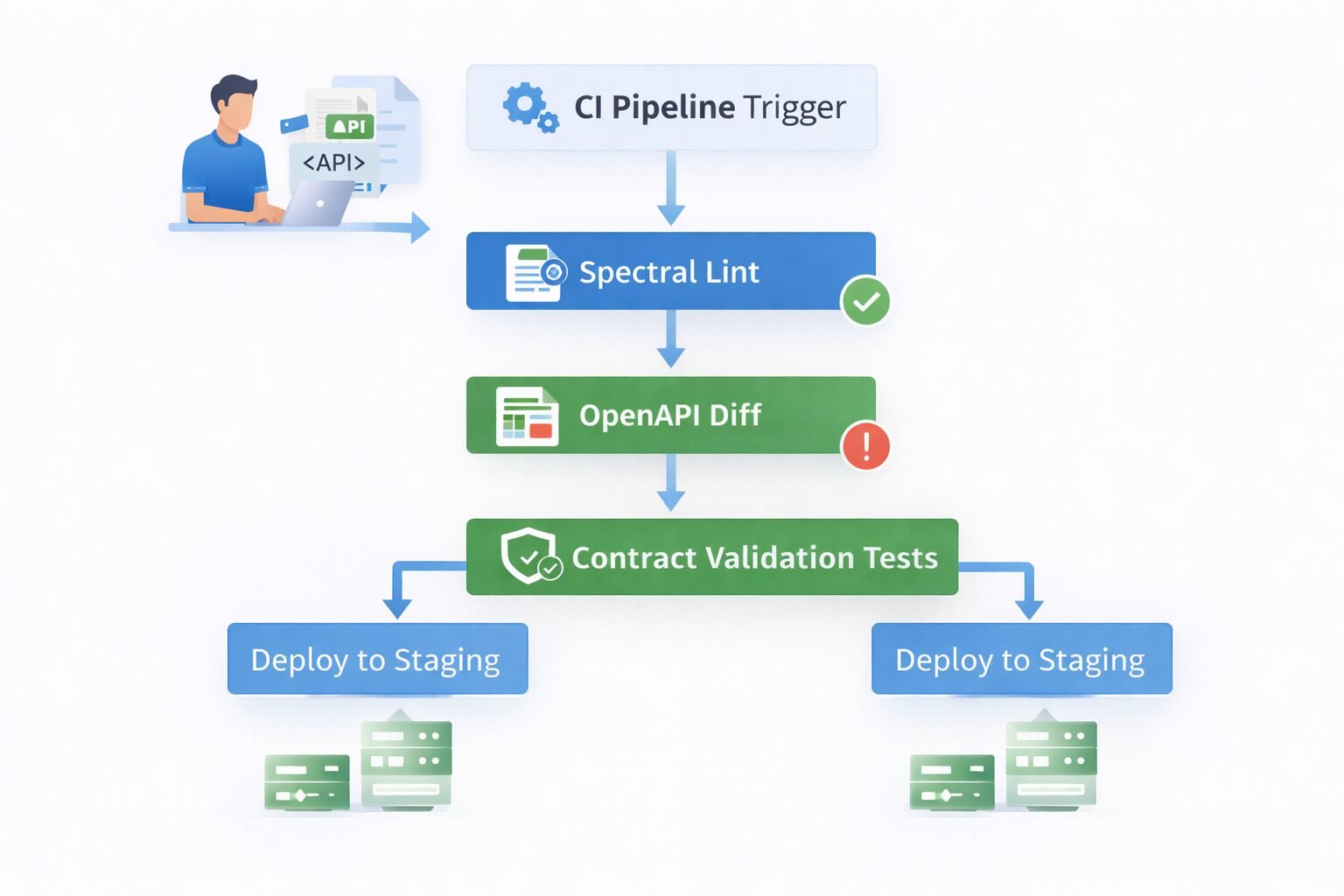
The contract is only a source of truth if the implementation is continuously validated against it. Without automated validation, the contract drifts from implementation just as documentation drifts from code in a code-first workflow slowly, silently, and expensively.
Server-Side Contract Validation
My team uses OpenAPI validation middleware that validates every request and response against the specification at runtime in non-production environments. In development and staging, a response that does not match the spec fails with a validation error that surfaces immediately. In production, validation runs in audit mode — logging mismatches without failing requests — to avoid user-facing failures from spec drift.
The tools vary by language ecosystem. For Node.js APIs, express-openapi-validator validates requests and responses against the spec automatically. For Python, connexion binds route handlers directly to spec operations and validates at the framework level.
The key principle is that validation is automatic, not manual. Engineers should not need to remember to check their responses against the spec — the pipeline does it for them.
Linting the Contract Itself
The contract needs to be linted for quality, not just syntactic validity. My team runs Spectral — an OpenAPI linting tool — in CI against every spec change. Spectral enforces:
- Every endpoint has an
operationId - Every response has an example
- Every error response references the standard error schema
- Naming conventions are applied consistently — snake_case field names, kebab-case paths, plural resource names
- No inline schemas — all schemas use
$refreferences - Every endpoint has at least one
4xxresponse defined
These rules are not stylistic preferences — they are quality gates that prevent spec quality from degrading under feature development pressure. A spec that fails linting does not merge.
Consumer-Driven Contract Testing
For internal service-to-service APIs, my team uses consumer-driven contract testing with Pact. Rather than defining the contract from the producer side only, each consumer publishes a “pact” — a record of exactly which endpoints and response fields it depends on. The producer’s CI pipeline validates that its implementation satisfies every consumer’s pact before deployment.
This pattern catches breaking changes before deployment in a way that static spec validation cannot. A producer that removes a field from a response might still pass its own contract validation — the spec may not require the field. But if a consumer’s pact requires it, the pipeline catches the break before it reaches production.
Consumer-driven contract testing is the most mature form of contract-first development because it makes the contract a living artifact updated by actual consumption patterns rather than assumptions about what consumers need.
Code Generation From the Contract
Once the contract is the authoritative source of truth, generating code from it becomes a force multiplier. My team generates the following artifacts from the OpenAPI specification automatically:
Server stubs: Route handlers with request validation and response type definitions. Engineers implement business logic inside the generated stubs rather than writing route infrastructure from scratch. This guarantees that route signatures match the spec because they are derived from it.
Client SDKs: Type-safe client libraries for every language ecosystem that consumes the API. Generated SDKs update automatically when the spec changes, eliminating the manual SDK maintenance burden that plagues most API teams. If you are integrating with external APIs like Google Calendar or Twilio, the quality of their generated SDKs is a direct reflection of how rigorously their contract is maintained.
Documentation: Interactive API documentation — Swagger UI, Redoc, Stoplight Elements — generated directly from the spec. Because the spec is the source of truth and is continuously validated against the implementation, the documentation is always accurate. This closes the documentation drift problem entirely.
Type definitions: TypeScript interfaces, Python dataclasses, Go structs. When the spec changes, the type definitions regenerate. Type mismatches between the spec and the implementation become compile-time errors rather than runtime surprises.
Validation schemas: Request validation logic derived from the spec’s required fields, type definitions, format constraints, and pattern validators. Engineers do not write validation code — they write spec constraints and the validation code is generated.
Versioning and Contract Evolution
Contract-first development changes the mechanics of API versioning in important ways. Because the contract is explicit and machine-readable, detecting breaking changes is automatable.
Automated Breaking Change Detection
My team runs openapi-diff or oasdiff in CI on every spec change. These tools compare the proposed spec against the current production spec and classify every change as breaking or non-breaking according to a defined ruleset.
Breaking changes — removing fields, changing types, adding required request fields, removing endpoints — fail the CI pipeline automatically. Non-breaking changes — adding optional fields, adding endpoints, relaxing validation constraints — pass without intervention.
This automation does two things. It prevents accidental breaking changes from reaching production without intentional versioning. And it removes the cognitive burden from engineers who should not need to manually evaluate every spec change for backward compatibility.
Managing Multiple Contract Versions
When a breaking change is intentional, my team maintains the previous contract version alongside the new one. The spec for v1 lives at specs/v1/openapi.yaml. The spec for v2 lives at specs/v2/openapi.yaml. Both are linted, both have mock servers, both generate validation middleware for their respective route handlers.
This makes versioning a documentation-first process. The version boundary is defined in the spec before any implementation changes. Implementation follows the contract, not the other way around. The deprecation headers and sunset dates that communicate the version lifecycle to clients are also specified in the contract — as spec extensions — before they appear in response headers.
Security Design in the Contract
Contract-first development is an opportunity to design security requirements explicitly before implementation, rather than retrofitting authentication and authorization constraints after the fact.
OpenAPI security schemes define authentication requirements at the spec level:
components:
securitySchemes:
BearerAuth:
type: http
scheme: bearer
bearerFormat: JWT
OAuth2:
type: oauth2
flows:
authorizationCode:
authorizationUrl: https://auth.example.com/oauth/authorize
tokenUrl: https://auth.example.com/oauth/token
scopes:
payments:read: Read payment data
payments:write: Create and modify paymentsEvery endpoint in the spec explicitly declares which security scheme and which scopes it requires. This makes authorization requirements visible in the contract — reviewable before implementation, testable automatically, and documentable without additional effort.
My team’s spec linting rules require every endpoint to declare a security requirement. An endpoint without a declared security requirement fails the lint check. This prevents unauthenticated endpoints from being shipped accidentally — a security control that costs nothing to implement in a contract-first workflow and is expensive to retrofit in a code-first workflow.
For teams managing JWT-based authentication and OAuth 2.0 flows, defining security schemes in the contract makes the authentication architecture visible and reviewable in the same artifact as the API design. Implementing OAuth 2.0 in REST APIs and calling REST APIs with OAuth tokens both become more straightforward when the OAuth flow is defined in the spec from day one — consumers know exactly which scopes to request before writing a line of integration code.
The security design in the contract also informs common API authentication vulnerabilities to avoid. When security requirements are explicit in the spec, security review can happen at the design stage rather than the penetration testing stage.
Error Contract Design
Error handling is part of the contract, not an afterthought. My team’s spec defines every error response with the same rigor as success responses — specific schemas, specific status codes, and specific error codes for every failure mode an endpoint can produce.
This connects directly to the error handling patterns in distributed APIs — the error envelope, the machine-readable error codes, the retryable field, and the docs_url are all defined in the spec before any error handling code is written. The contract tells consumers exactly what errors to expect and how to handle them, before they ever hit the endpoint in production.
For each endpoint, my team specifies:
- Every
4xxresponse with its specific error schema - The
422validation error schema with field-level detail - The
429rate limit response withRetry-Afterheader definition - The
503transient failure response withretryable: truein the body schema
Linting enforces that no endpoint ships without at least one 4xx response defined. An endpoint that only defines 200 responses has not been designed — it has been sketched.
Whether an API should return 400, 500, or always return 200 are not questions engineers should be answering independently per endpoint — they should be answered once in the contract design standards and enforced by linting rules across all endpoints. How to fix API error 400 and how to fix API errors generally become answerable from the spec itself when error contracts are designed explicitly.
Pagination in the Contract
Pagination strategy is a contract-level decision, not an implementation detail. My team defines the pagination envelope — cursor fields, has_next_page, per_page — as a shared schema component referenced by every collection endpoint. The pagination strategy for each endpoint is visible in the spec before any query code is written.
This matters because changing pagination strategy after implementation is a breaking change. Designing it in the contract first — and getting consumer buy-in before implementation — prevents the forced migration that happens when a team discovers that their offset-based pagination does not scale at 10 million records.
Common Mistakes My Team Has Seen
- Writing the spec after the code. This produces documentation, not a contract. The spec reflects the implementation rather than driving it, and drift begins immediately.
- Not running spec linting in CI. Manual spec quality is not maintainable under feature development pressure. Automate the quality gates.
- Inline schemas instead of
$refreferences. Inline schemas cannot be reused, cannot be shared across spec versions, and make the spec unreadable at scale. Use$reffor everything. - No examples in the spec. Examples are required for mock server generation and for documentation quality. A spec without examples is half a spec.
- Not involving consumers in contract design. A contract designed by backend engineers alone optimizes for the implementation, not the consumer. Consumer input during design is what makes contract-first development valuable.
- Treating the contract as documentation rather than a source of truth. If the contract is not validated against the implementation continuously, it drifts. Continuous validation is what separates contract-first development from contract-and-then-code-first development.
- No breaking change detection automation. Manual review of spec changes for backward compatibility is unreliable. Automate it.
- Skipping security scheme definitions. Leaving security out of the spec makes authorization requirements invisible to reviewers, consumers, and automated tooling. Every endpoint needs a declared security requirement.
When Not to Use Contract-First Development
Contract-first development has overhead — the spec must be written and reviewed before implementation begins, tooling must be configured and maintained, and the team must be disciplined about treating the spec as the source of truth. This overhead is justified in specific contexts and is overkill in others.
Exploratory prototyping where the API shape is genuinely unknown benefits from code-first iteration. When you do not know what the API should do yet, writing a spec first is premature. Build a working prototype, stabilize the interface, then formalize the contract before opening it to external consumers.
Internal APIs with co-located consumers where the producer and consumer are the same team and deploy together can use looser contract discipline. The coordination cost of cross-team contract alignment is the primary value driver of contract-first development — when that coordination overhead does not exist, the value is lower.
Highly experimental features behind feature flags that will change significantly before general availability do not benefit from formal contract discipline. Lock the contract once the feature stabilizes and is ready for general consumption.
Very simple APIs — a handful of endpoints, a single consumer, a bounded domain — where the contract is so simple that a well-written README suffices. Contract-first tooling adds ceremony that exceeds the value for truly simple API surfaces.
The inflection point where contract-first development becomes clearly worth the overhead: more than three consumers, more than one team involved in development, any external integration partners, or any context where API stability is a customer commitment.
Enterprise Considerations
Enterprise procurement processes evaluate API maturity as a proxy for vendor reliability. A vendor who can demonstrate contract-first development practices, automated breaking change detection, and generated SDK availability signals engineering maturity that translates directly to integration risk reduction.
SDK availability: Enterprise integration teams budget significant time for SDK development when none is available. A vendor with generated, type-safe SDKs in the languages the enterprise uses reduces integration cost by weeks. This is not a nice-to-have — for enterprise deals above a certain size, SDK availability is a checklist item. Contract-first development makes SDK generation automatic.
Sandbox environment: The mock server generated from the contract is your sandbox environment. Enterprise customers doing technical due diligence can build and test against the sandbox before signing a contract. The sandbox is always up-to-date because it is generated from the current spec. This eliminates the “sandbox is broken” support category that plagues manually maintained test environments.
Compliance documentation: In regulated industries, the API contract is a compliance artifact. Financial services integrations often require documentation of every field transmitted, its data type, and its retention implications. An OpenAPI spec with complete schema definitions and field descriptions satisfies this requirement directly. Teams automating invoice generation or implementing role-based access after payment have compliance documentation requirements that a well-maintained spec satisfies without additional effort.
Change management: Enterprise customers need advance notice of API changes. Contract-first development makes this process systematic — a proposed spec change generates a diff that is shared with affected consumers during a notification period before implementation begins. The change is visible in a format consumers can evaluate technically before it is in production.
Cost & Scalability Implications
The Frontend Parallelization Dividend
The most immediate cost benefit of contract-first development is frontend and backend development running in parallel rather than sequentially. In a team where backend and frontend engineers have equivalent day rates, sequential development means frontend engineers are idle — or working on unrelated tasks — while backend engineers build the API. Parallelization from day one of a feature cycle recaptures that idle time.
My team estimates a 30–40% reduction in total feature delivery time on integration-heavy features when contract-first development is applied consistently. This is not a theoretical estimate — it comes from tracking cycle time before and after adopting contract-first practices on comparable features.
Reduced Integration Bug Rate
Integration bugs — mismatches between what the API returns and what the consumer expects — are expensive to diagnose and fix because they require coordination between teams, are often environment-dependent, and frequently surface in production rather than in development. Contract validation in CI catches integration bugs at the cheapest possible point — before code is merged.
My team tracks integration bug rate as a quality metric. After adopting contract-first development with CI validation, integration bug rate dropped by roughly 60% in the first quarter. The remaining 40% were behavioral mismatches — cases where the spec was correct but the semantic behavior was misunderstood — which drove improvements in documentation quality.
Documentation Maintenance at Zero Marginal Cost
In a code-first workflow, documentation is a separate deliverable that competes with feature development for engineering time. In a contract-first workflow, documentation is generated from the spec automatically. The marginal cost of keeping documentation current is zero — updating the spec updates the documentation simultaneously.
At scale, this compounds significantly. A platform with 200 endpoints, each requiring documentation maintenance, generates substantial ongoing documentation overhead in a code-first workflow. In a contract-first workflow, that overhead is effectively eliminated. Teams using headless CMS platforms or Next.js-based developer portals can publish generated API documentation directly into their developer experience without a separate authoring workflow.
Implementing This Correctly: A Strategic Perspective
Contract-first development is an organizational practice as much as a technical one. The tooling is straightforward — OpenAPI, Prism for mocks, Spectral for linting, oasdiff for breaking change detection, code generators for your language ecosystem. The harder part is the cultural shift: engineers who are accustomed to writing code first need to internalize that the spec is the deliverable, not the implementation.
My team phases the adoption in three steps. First, establish the spec as a required artifact on all new API work. Existing APIs get retrofitted specs over time — prioritizing the highest-traffic and most consumer-facing endpoints first. Second, add CI validation — spec linting, contract compliance checking, and breaking change detection. Make the spec a gated artifact the same way tests are gated. Third, add code generation for at least one artifact — typically client SDKs or documentation — to make the productivity dividend of contract-first development tangible to the engineering team.
The organizational unlock comes when consumer teams — frontend, mobile, integration partners — start treating the spec as their primary reference and filing spec issues rather than Slack messages when something is unclear. At that point, the contract is functioning as a genuine source of truth and the investment has compounded into a platform-wide asset.
APIs built contract-first are APIs that scale organizationally as well as technically. They onboard new team members faster, support enterprise procurement processes more cleanly, and accumulate less integration debt over time. The spec is not overhead — it is the engineering investment that pays dividends for the lifetime of the interface.

Finly Insights Team is a group of software developers, cloud engineers, and technical writers with real hands-on experience in the tech industry. We specialize in cloud computing, cybersecurity, SaaS tools, AI automation, and API development. Every article we publish is thoroughly researched, written, and reviewed by people who have actually worked in these fields.


