

Executive Summary
Error handling in distributed systems is not about catching exceptions — it is about designing failure contracts. When a payment service times out, when a downstream dependency returns a 503, when a message queue consumer processes a malformed event for the sixth time, the quality of your error handling determines whether the system recovers gracefully or cascades into an outage. This article covers how my team designs error handling systems that are observable, recoverable, and honest with clients under real production failure conditions.
The Real Problem This Solves
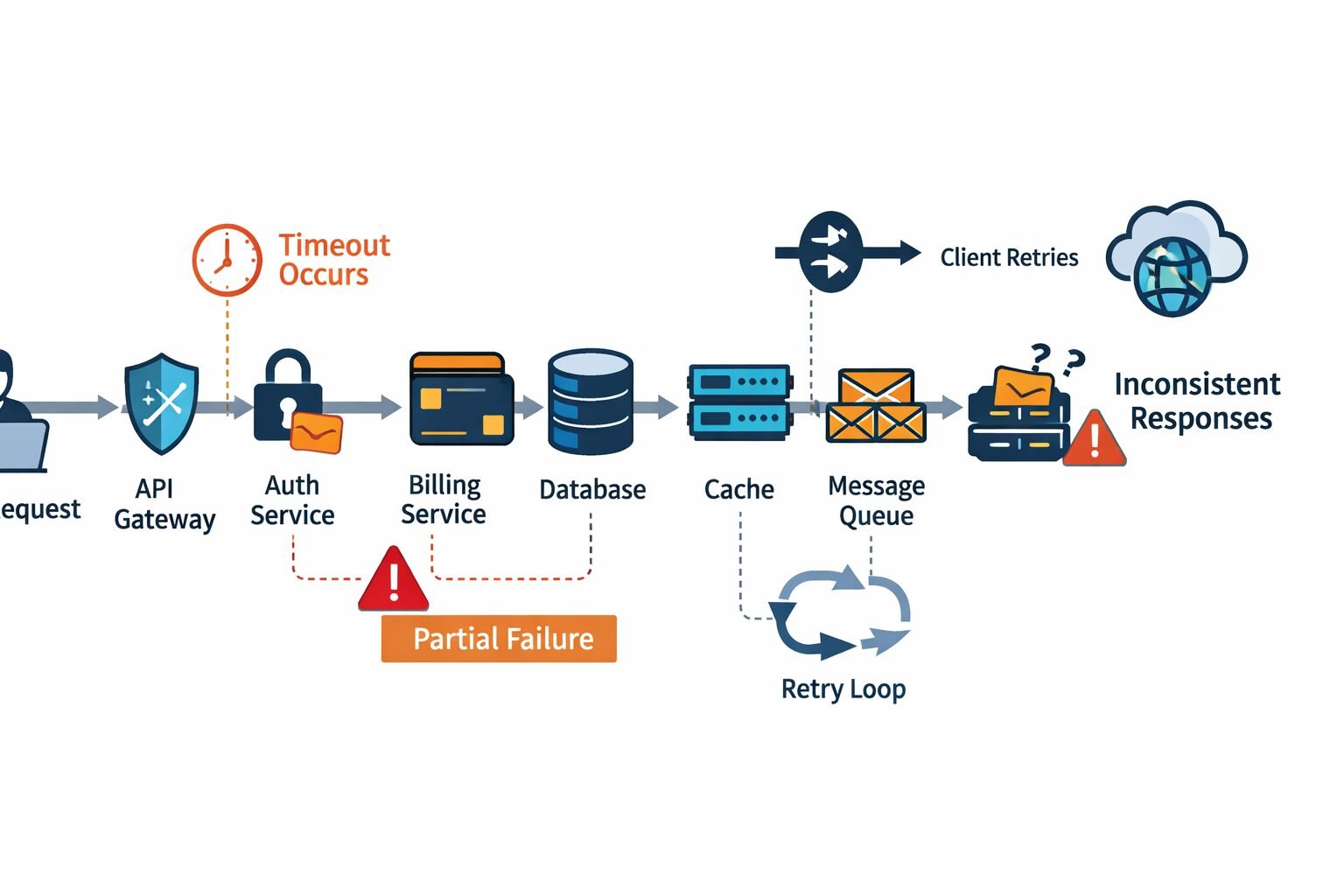
A single-process application has one failure domain. When something goes wrong, the call stack tells you exactly where, the error propagates synchronously, and rollback is straightforward. Distributed systems destroy all three of those properties simultaneously.
In a distributed API, a single user-facing operation might touch an authentication service, a billing service, a database, a cache layer, a message queue, and two third-party APIs. Any of those components can fail independently, fail partially, fail silently, or fail in ways that look like success. The request that triggered the operation might be retried — by the client, by a load balancer, by an orchestration layer — before the original failure has fully resolved.
My team has done post-mortems on distributed system outages where the root cause was not the original failure — it was the error handling around the failure. A timeout that returned a 500 instead of a 503 caused a client to stop retrying instead of backing off. A validation error that swallowed field-level detail forced a developer to instrument the production system to reproduce the bug. A circuit breaker that opened too aggressively took down a healthy service because one downstream dependency was slow.
These failures are preventable. They require treating error handling as a first-class architectural concern, not an afterthought bolted onto working code.
The Error Taxonomy Every Distributed System Needs
Before writing a single error handler, my team establishes a shared error taxonomy. Without it, every service invents its own error vocabulary, and the API surface becomes a patchwork of inconsistent failure signals that clients cannot reason about uniformly.
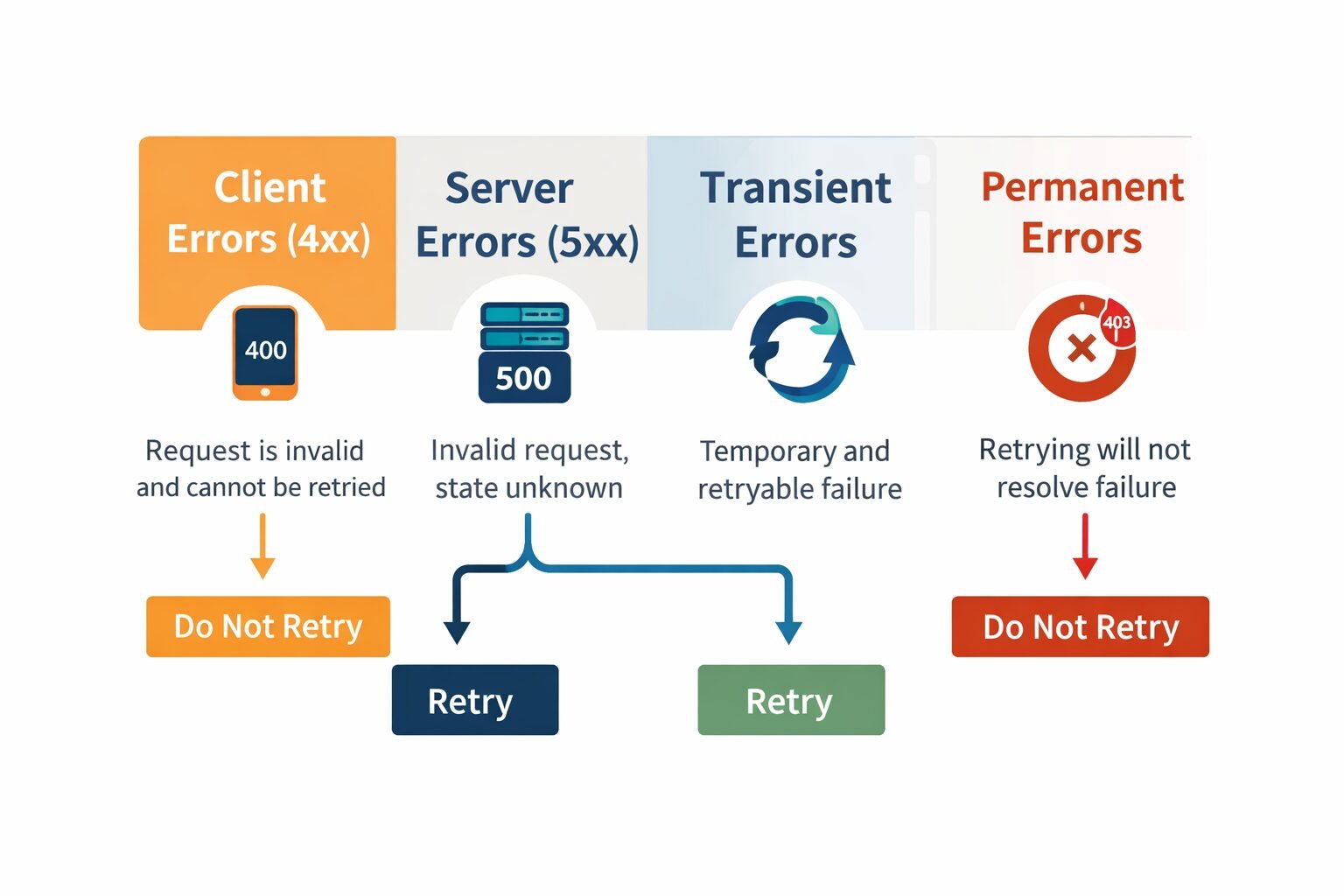
The Four Error Categories
Client errors (4xx): The request is invalid and resubmitting it without modification will produce the same result. These errors are the client’s responsibility to fix. They should never trigger automatic retries.
Server errors (5xx): The server failed to process a valid request. The client should not assume the operation succeeded or failed definitively — the state is unknown. Retrying may be appropriate depending on the specific code.
Transient errors: A subset of server errors where the failure is temporary and retrying after a backoff will likely succeed. Network timeouts, rate limit responses, and temporary downstream unavailability fall here.
Permanent errors: Failures that will not resolve with retrying. Authorization failures, resource not found, schema validation failures. Retrying these wastes resources and delays client-side remediation.
The most important design decision in this taxonomy is making transient versus permanent failure status explicit in your error responses — not leaving clients to infer it from status codes alone. My team includes a retryable boolean in every error response envelope. Clients should not need to maintain a lookup table of which status codes are safe to retry.
The Standard Error Envelope
Every error response across every service in my team’s systems uses this structure:
{
"error": {
"code": "payment_method_declined",
"message": "The payment method was declined by the issuing bank.",
"retryable": false,
"request_id": "req_01HX4K9MNPQR",
"timestamp": "2024-03-15T14:23:01Z",
"details": [
{
"field": "card_number",
"code": "card_declined",
"message": "Card was declined. Contact your bank for details."
}
],
"docs_url": "https://docs.example.com/errors/payment_method_declined"
}
}
```
Every field earns its place. `code` is machine-readable and stable across API versions. `message` is human-readable and subject to change — clients must never parse it programmatically. `retryable` removes ambiguity about retry behavior. `request_id` enables support escalation without requiring clients to reproduce the error. `docs_url` reduces support ticket volume by giving developers a direct path to remediation guidance.
This envelope design connects directly to consistent [API naming conventions](https://finlyinsights.com/api-naming-conventions-that-scale/) — the fields in your error response are part of your API contract and need the same naming discipline as your success responses.
---
## HTTP Status Code Discipline
Status codes are the first signal a client receives about what went wrong. Using them incorrectly creates systemic confusion that multiplies across every integration.
### The Codes That Matter Most
**400 Bad Request:** The request body or parameters are malformed or invalid. Always include field-level detail in the `details` array. A 400 without detail forces the client to guess which field failed validation. Understanding [when an API should return 400](https://finlyinsights.com/when-should-an-api-return-400/) is foundational — this code should be reserved for client-side input errors, not server-side processing failures.
**401 Unauthorized:** The request lacks valid authentication credentials. Not "you don't have permission" — that is 403. "We don't know who you are." Clients should re-authenticate and retry.
**403 Forbidden:** The authenticated identity lacks permission for this operation. Do not retry. Escalate within the application.
**404 Not Found:** The resource does not exist. In multi-tenant systems, return 404 for resources the authenticated identity lacks access to — not 403. Returning 403 confirms the resource exists, which leaks information. This is a security decision disguised as an error handling decision.
**409 Conflict:** The request conflicts with current resource state. A duplicate creation attempt, a concurrent modification conflict, or an idempotency key collision. Not retryable without resolving the conflict first. This is central to [designing idempotent APIs at scale](https://finlyinsights.com/designing-idempotent-apis-at-scale/) — 409 is the correct response when an idempotency key collision is detected mid-processing.
**422 Unprocessable Entity:** The request is syntactically valid but semantically invalid. The JSON parses correctly, the fields are present, but the values violate business rules. My team uses 422 for business logic validation failures and 400 for structural validation failures. This distinction gives clients programmatic signal about which layer rejected the request.
**429 Too Many Requests:** Rate limit exceeded. Always include `Retry-After` header. Always include the rate limit context — which limit was hit, what the limit is, when it resets. A 429 without retry guidance is an error about an error. Clients integrating with your [rate limiting strategy](https://finlyinsights.com/api-rate-limiting-strategies-for-high-traffic-applications/) need this information to implement correct backoff. This is also why [how to avoid hitting API rate limits](https://finlyinsights.com/how-to-avoid-hitting-api-rate-limits/) is a client-side concern that depends entirely on the server providing actionable rate limit headers.
**500 Internal Server Error:** Something unexpected failed. Log the full error server-side. Return nothing sensitive to the client. Include the `request_id` so support can correlate. Whether an [API should return 500](https://finlyinsights.com/should-api-return-500/) versus a more specific 5xx code is worth deliberate thought — 500 signals unexpected failure, while 502 and 503 signal known dependency failures.
**502 Bad Gateway:** An upstream dependency returned an invalid response. This is retryable — the upstream may recover.
**503 Service Unavailable:** The service is temporarily unable to handle requests. Always include `Retry-After`. This is the correct code for circuit breaker open states, maintenance windows, and temporary overload conditions.
**504 Gateway Timeout:** An upstream dependency timed out. Retryable with backoff. Critically different from 500 — a 504 tells the client that the operation state is unknown, not that it definitively failed.
The question of [whether an API should always return 200](https://finlyinsights.com/should-api-always-return-200/) comes up repeatedly in my team's design reviews. The answer is never. Wrapping errors in 200 responses to satisfy clients who only check status codes destroys observability, breaks monitoring, and forces every client to implement a second layer of error parsing.
---
## Error Propagation in Service Meshes
### The Translation Problem
In a microservices architecture, errors travel across service boundaries. A downstream payment service returns a 402. The order service that called it needs to decide: pass the 402 upstream to the client? Translate it to a different code? Absorb it and return a different error entirely?
My team follows a strict error translation protocol. Services translate downstream errors into their own error vocabulary rather than passing them through verbatim. This keeps the internal service topology invisible to external clients and prevents internal error codes from leaking into the public API contract.
The translation layer at each service boundary handles three cases:
**Direct translation:** The downstream error maps cleanly to an upstream error. A 404 from the user service becomes a 404 from the order service with a translated message.
**Abstracted translation:** The downstream error is an implementation detail. A database constraint violation becomes a 409 Conflict. A third-party API timeout becomes a 503 with a generic "dependency unavailable" message.
**Escalation:** The downstream error is unexpected and unhandled. The service logs the full downstream error, generates a `request_id`, and returns a 500 to the upstream caller.
### Preserving Request IDs Across Service Boundaries
Every service in my team's architecture propagates the original request ID through all downstream calls via a `X-Request-Id` header. When an error occurs anywhere in the call chain, every log entry — across every service — contains the same request ID. This transforms error debugging from "find the needle in ten haystacks" into "grep for the request ID across all log streams."
Without this, correlating a client-reported error to a root cause in a downstream service requires reconstructing the call chain from timestamps and service logs — a process that typically takes 30–60 minutes and requires engineers who know the service topology. With consistent request ID propagation, correlation takes seconds.
---
## Retry Strategies and Backoff Patterns
### Exponential Backoff With Jitter
When a retryable error occurs, clients must not retry immediately or at fixed intervals. Immediate retries amplify the load on an already-stressed system. Fixed-interval retries produce synchronized retry storms when multiple clients hit the same error simultaneously.
The correct pattern is exponential backoff with jitter:
```
wait_time = min(base_delay * (2 ^ attempt) + random_jitter, max_delay)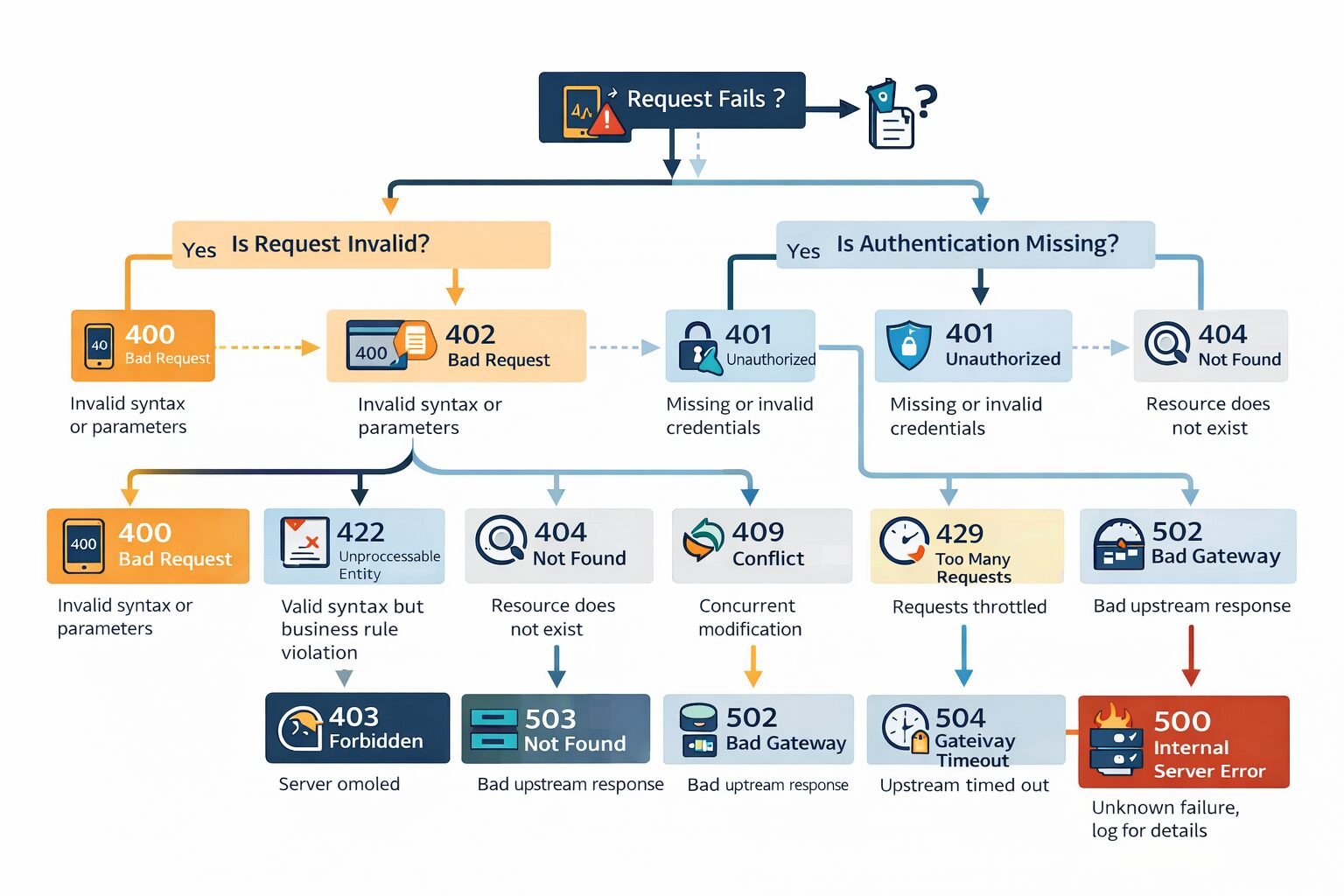
My team defaults to base_delay = 1s, max_delay = 32s, and jitter = random(0, 1s). This spreads retry load across a time window and prevents the thundering herd problem where every client retries at the same moment.
The Retry-After header takes precedence over backoff calculations when present. If the server specifies a retry window — for 429 responses and 503 responses — clients must respect it rather than using their own backoff schedule.
Retry Budgets
Unlimited retries are not a resilience strategy — they are a denial-of-service attack on your own infrastructure. My team implements retry budgets at the client level: a maximum of three retries per request, with the exponential backoff schedule above. Beyond three retries, the operation is marked as failed and escalated to a dead letter queue or a human intervention workflow.
At the service level, my team uses retry budgets as a circuit breaker signal. If a service is consuming its entire retry budget on a downstream dependency consistently, that is a leading indicator of dependency degradation — often detectable minutes before the dependency fully fails.
Idempotency and Retry Safety
Retrying a request is only safe if the operation is idempotent. Before implementing any retry logic, my team verifies that the target endpoint is safe to retry. Non-idempotent operations — those that create resources or trigger side effects — must not be retried without an idempotency key. This is the direct operational intersection of retry strategy and idempotent API design — the two concerns are inseparable in production systems. The broader context of API timeouts and retries in distributed systems covers the full failure surface that retry strategies need to account for.
Circuit Breakers: Failing Fast on Known Bad Dependencies
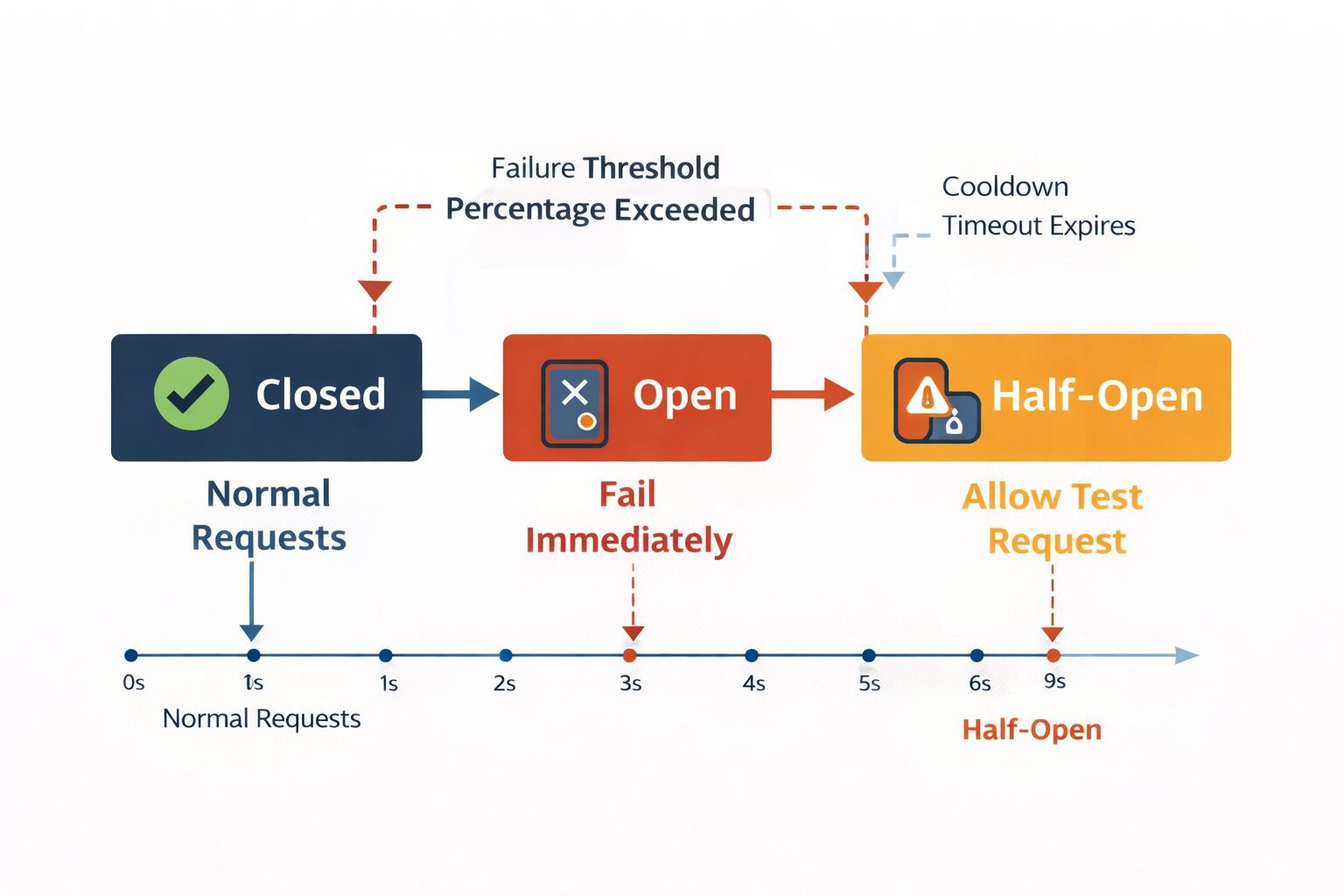
The Pattern
A circuit breaker wraps calls to a downstream dependency and tracks the failure rate over a rolling time window. When failures exceed a threshold — my team typically uses 50% failure rate over a 60-second window — the circuit breaker opens. While open, calls to the dependency fail immediately without actually making the network request. After a configurable timeout, the circuit breaker enters a half-open state and allows a single probe request. If the probe succeeds, the circuit closes. If it fails, the circuit stays open.
The value is in the fast failure. An open circuit breaker returns a 503 in microseconds instead of waiting for a 30-second timeout. This protects the upstream service’s thread pool and response time budget from being consumed by a dependency that is clearly unavailable.
Tuning Circuit Breakers Without Breaking Healthy Systems
The most common circuit breaker mistake my team sees is misconfigured thresholds that open the circuit on transient blips rather than genuine dependency failures. A circuit breaker that opens on a 10-second window with a 30% failure threshold will open during normal deployment rollouts, brief network hiccups, and legitimate traffic spikes — generating false positive outages that are worse than the problem they are solving.
My team tunes circuit breakers with three parameters in tension: window size, failure threshold, and minimum request volume. The minimum request volume parameter — often overlooked — prevents the circuit from opening when failure rate is 100% because exactly one request failed in a quiet period. Require at least 20 requests in the window before evaluating the failure rate.
Circuit Breakers and API Gateways
If you are running requests through an API gateway, circuit breaker logic can live at the gateway level rather than in each service. API gateways that handle rate limiting can also manage circuit breaker state centrally, which gives you a single control plane for both concerns and prevents individual services from needing to independently track downstream dependency health.
Dead Letter Queues and Poison Message Handling
The Problem With Unlimited Retries in Event-Driven Systems
In event-driven architectures, errors do not always surface synchronously. A message consumer that fails processing will retry the message — often indefinitely — if the retry logic is not carefully bounded. A message that cannot be processed due to a schema change, a bug, or a data anomaly becomes a poison message: it blocks the queue, consumes retry budget, and generates noise in monitoring that obscures real failures.
My team implements dead letter queues (DLQs) as the final destination for messages that exceed the retry budget. After a configurable number of failed processing attempts — typically three to five — the message is moved to the DLQ rather than retried further.
DLQ Design Principles
DLQs must be monitored. A DLQ that accumulates messages silently is a data loss event masquerading as a system property. My team triggers alerts when DLQ depth exceeds a threshold and reviews DLQ contents in daily operational reviews.
DLQ messages must be replayable. After fixing the bug or schema issue that caused processing failures, the DLQ needs to be drained back into the main queue. Design your message processing to be idempotent so that replayed messages do not cause duplicate side effects. Idempotency patterns apply to message processing exactly as they apply to HTTP requests — derived keys, state machine checks, and atomic operations all transfer directly.
Preserve the original message. DLQ messages should contain the original payload without modification, alongside metadata about when processing failed, how many times it was retried, and what error was produced on the final attempt. This metadata is what turns a DLQ investigation from archaeology into diagnosis.
Observability: Errors You Cannot See Cannot Be Fixed
Structured Error Logging
Every error that occurs in production should generate a structured log event with enough context to diagnose it without reproducing it. My team’s error log schema includes: request ID, user ID, tenant ID, service name, error code, error message, stack trace, upstream service name (if applicable), downstream error code (if applicable), and request duration.
The request duration field is frequently omitted but critically important. An error that takes 28 seconds to produce is a timeout. An error that takes 3ms to produce is a validation failure or a cache hit on a known bad state. Duration changes the diagnosis entirely.
Error Rate Alerting vs. Error Volume Alerting
Most teams alert on error volume: “more than 100 errors in 5 minutes.” This generates false positives during traffic spikes — a 10x traffic increase with a stable 0.1% error rate doubles error volume without indicating a problem. My team alerts on error rate — the percentage of requests resulting in errors — with a minimum request volume floor to prevent alert storms during low-traffic periods.
Separate alert thresholds for 4xx and 5xx errors. A spike in 4xx errors indicates a client integration problem or a breaking API change — important to investigate, but not a system health emergency. A spike in 5xx errors indicates a system health problem that needs immediate response.
Distributed Tracing for Error Propagation
When an error surfaces at the API layer but originates three services deep in the call chain, logs alone are insufficient. My team uses distributed tracing — OpenTelemetry is the standard — to produce a complete trace of every request across all service boundaries. When an error occurs, the trace shows exactly which service originated the failure, what the downstream context was, and how the error propagated up the call chain.
The investment in distributed tracing pays off disproportionately during incidents. Reducing mean time to diagnosis from 45 minutes to 5 minutes across a team of ten engineers is a measurable operational improvement that directly affects system reliability.
Common Mistakes My Team Has Seen
- Returning 200 with an error body. This destroys monitoring, breaks client retry logic, and forces a second layer of error parsing. Always use the correct HTTP status code.
- Generic error messages in production. “An error occurred” is not an error message — it is a support ticket. Include enough context for a developer to act without contacting support.
- Not including
request_idin error responses. Support escalations without request IDs require reproducing the error. Reproduction is often impossible for timing-dependent failures. Always include the request ID. - Swallowing errors in middleware. Framework middleware that catches all exceptions and returns a generic 500 hides the original error type and prevents correct status code mapping. Catch specific exceptions and map them to specific status codes.
- Retrying non-idempotent operations. A retry loop on a
POST /chargesendpoint without an idempotency key will create duplicate charges. Verify idempotency before implementing retries. - Circuit breakers without minimum volume thresholds. A single failed request in a quiet period should not open a circuit. Set minimum volume before evaluating failure rates.
- DLQs without monitoring. Silent DLQ accumulation is silent data loss. Monitor DLQ depth as a first-class operational metric.
- Inconsistent error envelopes across services. Clients integrating with multiple services in your platform should not encounter structurally different error responses. Standardize the envelope at the platform level. This is the same argument that drives API versioning strategies — consistency is a contract, not a courtesy.
When Not to Use These Patterns
Sophisticated error handling infrastructure has overhead — code complexity, operational complexity, and latency budget. Not every system needs every pattern.
Simple CRUD APIs with a single service boundary do not need circuit breakers. If your API is a thin layer over a single database with no downstream service calls, circuit breaker logic adds complexity with no benefit.
Internal APIs with co-deployed consumers do not need the full error envelope. When both the producer and consumer are maintained by the same team and deployed together, a simpler error format with less ceremony is appropriate. Save the full envelope for external-facing surfaces.
Synchronous APIs where all failures are final do not need retry budgets or DLQs. If your API is stateless and every request is independent, the client’s own retry logic is sufficient without server-side retry infrastructure.
Low-traffic APIs under controlled load do not need sophisticated circuit breaker tuning. Circuit breakers are most valuable when failure in one component can cascade under high concurrency. At low traffic, cascading failures are less likely and the operational overhead of circuit breaker management exceeds the benefit.
Enterprise Considerations
Enterprise clients build long-lived integrations that must handle your API’s failure modes gracefully for years. The quality of your error contract directly affects how much defensive code they need to write on their side.
Error code stability: Enterprise integrations switch on your error codes programmatically. A change in error code vocabulary is a breaking change for every integration that handles that error. My team versions error codes alongside API versions and documents error code stability commitments explicitly. This connects to API versioning strategy — error codes need the same deprecation protocol as endpoint changes.
SLA error budgets: Enterprise SLAs typically specify error rate commitments — “less than 0.1% of requests will result in 5xx errors.” Measuring and reporting against these commitments requires the observability infrastructure described above. Error rate SLAs are unenforceable without structured error logging and rate-based alerting.
Compliance and audit: In regulated industries, error logs are audit artifacts. A complete record of every failed operation — with request context, error codes, and timestamps — satisfies audit requirements for financial services, healthcare, and government integrations. Design your error logging for compliance from the start rather than retrofitting it during an audit. Teams building role-based access controls after payment need to log authorization errors in particular — a 403 on a sensitive resource is both an operational signal and a security audit event.
Error documentation as a competitive differentiator: Stripe’s error documentation is famously thorough. Every error code has a dedicated page, a human-readable explanation, and recommended remediation steps. Enterprise buyers evaluate documentation quality during procurement. My team treats error documentation as a product artifact — it is written by the same team that designs the errors, reviewed in the same process, and updated in the same release cycle. The docs_url field in the error envelope is not decoration — it is a direct path to the documentation that converts a frustrated integration developer into a successful one.
Cost & Scalability Implications
Logging Volume at Scale
Structured error logging is inexpensive at low error rates and expensive at high error rates. At 10,000 RPS with a 0.1% error rate, you generate 10 error log events per second — negligible. At 100,000 RPS with a 1% error rate during an incident, you generate 1,000 error log events per second, each with a full stack trace. Log ingestion costs in managed observability platforms (Datadog, New Relic, Elastic) scale with volume and can spike dramatically during incidents — precisely when you most need the logs.
My team manages this with log sampling on high-volume error types. Once an error code has fired 100 times in a 60-second window, subsequent occurrences are sampled at 10% until the rate drops. This reduces log volume without losing the signal that the error is occurring — the count metric is still accurate, only the individual log entries are sampled.
Retry Load Amplification
Retry logic that is not carefully bounded amplifies load on degraded systems. If a service handles 10,000 RPS and begins returning 503s due to a dependency failure, and every client retries three times with 1-second backoff, the effective load on the service spikes to 40,000 RPS at exactly the moment it is least able to handle it. Circuit breakers prevent this by failing fast once the failure pattern is established, but the window between the first failures and circuit opening is the period of maximum retry amplification.
My team monitors retry rates as a leading indicator of dependency stress. A rising retry rate on a healthy service suggests a downstream dependency is beginning to degrade — often detectable minutes before the dependency returns enough errors to trigger alerting. This connects to understanding how API throttling differs from rate limiting — throttling is a deliberate flow control mechanism, while retry amplification is an emergent property of error handling under load, and confusing the two leads to misconfigured responses.
Implementing This Correctly: A Strategic Perspective
Error handling is the part of an API that clients hope never to see and absolutely depend on when things go wrong. The quality of your error handling is most visible during incidents — and incidents are when your relationship with enterprise customers is most at risk.
My team’s implementation starts with the error taxonomy and the standard envelope before writing any business logic. The error vocabulary is established as a shared artifact — documented, reviewed, and referenced by every service that joins the platform. New services do not invent error codes; they extend a shared registry.
The second layer is observability infrastructure: structured logging, distributed tracing, and rate-based alerting. These are not optional enhancements — they are prerequisites for operating a distributed system responsibly. An error you cannot observe is an error you cannot fix, and an error you cannot fix will eventually become an outage you cannot explain.
The third layer is the client-facing contract: error code documentation, stability commitments, and the docs_url field that connects every error response to actionable remediation guidance. This layer is what converts error handling from internal engineering infrastructure into external product quality.
APIs that handle errors well are APIs that enterprise customers trust with critical workflows. Error handling is not defensive programming — it is offensive architecture. Design it with the same intentionality as your happy path, document it with the same rigor as your successful responses, and treat every error code as a contract you are making with every developer who will ever integrate with your platform.

Finly Insights Team is a group of software developers, cloud engineers, and technical writers with real hands-on experience in the tech industry. We specialize in cloud computing, cybersecurity, SaaS tools, AI automation, and API development. Every article we publish is thoroughly researched, written, and reviewed by people who have actually worked in these fields.


